지혜의 개발공부로그
지혜의 개발공부로그
통계 - 분포, 정규분포, 왜도, 첨도
04 Aug 2025 | Statistics개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
분포
데이터가 전체 범위에서 어떻게 퍼져있는지를 나타내는 패턴
- 어떤 값 주변에 데이터가 얼마나 자주 등장하는지
- 데이터들이 어디에 몰려있는지 등을 설명함
왜 분포를 봐야 하는가?
- 평균이나 중앙값 등 단일 수치만으로는 데이터의 전체 모습을 알 수 없다
- 서로 다른 두 데이터가 같은 평균을 가질수는 있지만, 데이터의 퍼짐형태(=분포)는 전혀 다를수 있다
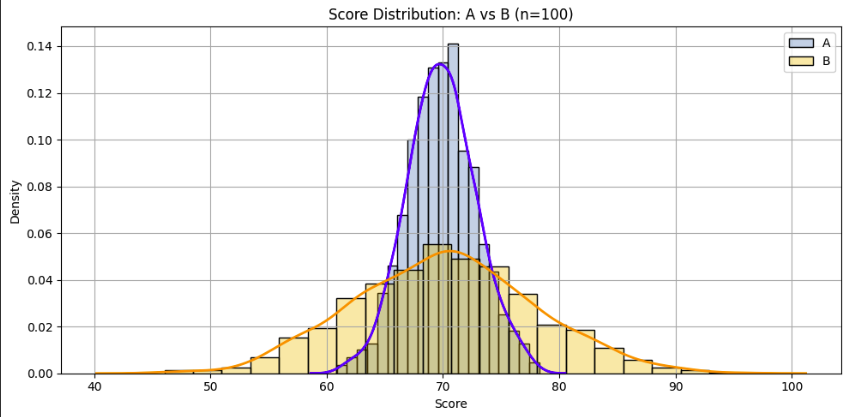
예시
- A의 시험 점수
- $70, 71, 69, 70, 70, 71, 69, 70$
- 대부분 70 근처에 몰려 있음 → 집중된 분포
- B의 시험 점수
- $40, 60, 80, 90, 70, 50, 100, 30$
- 점수가 넓게 퍼져 있음 → 흩어진 분포
- 둘 다 평균은 비슷하지만 분포는 매우 다름.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(0)
# A: 평균 70, 표준편차 1 (집중된 분포)
score_A = np.random.normal(loc=70, scale=3, size=1000)
# B: 평균 70, 표준편차 15 (넓게 퍼진 분포)
score_B = np.random.normal(loc=70, scale=8, size=1000)
plt.figure(figsize=(10, 5))
# 히스토그램 (확률 밀도 기준)
sns.histplot(score_A, kde=False, stat="density", bins=20, color="steelblue", label="A", alpha=0.3)
sns.histplot(score_B, kde=False, stat="density", bins=20, color="orange", label="B", alpha=0.3)
# KDE 선 그래프
sns.kdeplot(score_A, color="blue", linewidth=2)
sns.kdeplot(score_B, color="darkorange", linewidth=2)
plt.title("Score Distribution: A vs B (n=100)")
plt.xlabel("Score")
plt.ylabel("Density")
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
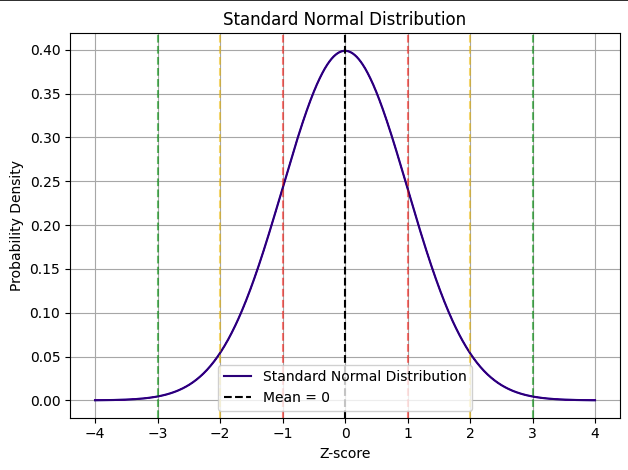
정규분포(Normal Distribution)
- 데이터가 평균을 중심으로 좌우 대칭으로 퍼지는 분포
- 그래프 형태가 종(bell) 모양을 가짐 > bell curve라고도 불림
- 많은 자연현상과 측정값, 사람의 키, 시험 점수 등이 정규분포를 따름
정규분포의 특징
- 평균, 중앙값, 최빈값이 모두 같음
- 좌우가 대칭
- 대부분의 데이터가 평균 근처에 몰려있음
- 멀어질수록 빈도가 떨어짐
- 종 모양 곡선을 그릴 수 있음
정규분포의 확률 분포 규칙 (68-95-99.7법칙)
- 평균 ± 1 표준편차 범위에 전체의 약 68% 포함
- 평균 ± 2 표준편차 → 약 95%
- 평균 ± 3 표준편차 → 약 99.7% → 이 범위 안에 대부분의 데이터가 있다는 의미
정규분포가 중요한 이유
- 많은 통계 분석 기법이 정규분포를 전제로 함(t-test, 회귀분석 등)
- 정규분포 위에서는 확률계싼, 이상값 판단, 신뢰구간 해석이 가능함
- 정규성을 만족하지 않으면 일반적인 검정 결과가 왜곡될 수 있음
- 정규분포는 평균이 곡선의 위치를 결정하고
- 표준편차가 곡선의 넓이와 뾰족함 정도를 결정
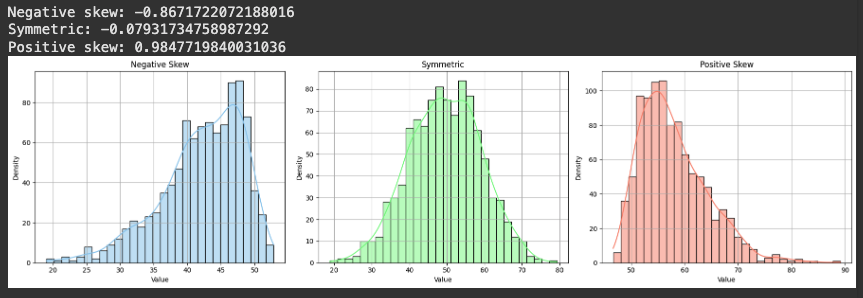
왜도(Skewness)
데이터 분포가 평균을 기준으로 좌우 대칭인지, 어느 한쪽으로 치우쳐있는 지를 나타내는 지표
- 정규분포의 왜도는 0, 완전한 대칭
- 하지만 데이터는 한쪽으로 더 몰리거나 꼬리가 길어지는 경우가 많음
- 왜도 > 분포가 얼마나 비대칭적으로 기울어져 있는지를 측정하는 정도
왜도의 종류
| 왜도 값 | 형태 | 설명 |
|---|---|---|
| 왜도 < 0 | 왼쪽 꼬리가 길다 | 음의 왜도, 평균 < 중앙값 |
| 왜도 = 0 | 좌우 대칭 | 정규분포에 가까움 |
| 왜도 > 0 | 오른쪽 꼬리가 길다 | 양의 왜도, 평균 > 중앙값 |
from scipy.stats import skew
np.random.seed(0)
# 데이터 생성
data_left = skewnorm.rvs(a=-6, size=1000) * 10 + 50 # 음의 왜도
data_normal = np.random.normal(loc=50, scale=10, size=1000) # 정규
data_right = skewnorm.rvs(a=6, size=1000) * 10 + 50 # 양의 왜도
# 왜도 값 출력
print("Negative skew:", skew(data_left))
print("Symmetric:", skew(data_normal))
print("Positive skew:", skew(data_right))
# 시각화
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
# 음의 왜도
sns.histplot(data_left, bins=30, kde=True, color='skyblue', ax=axes[0])
axes[0].set_title("Negative Skew")
axes[0].set_xlabel("Value")
axes[0].set_ylabel("Density")
axes[0].grid(True)
# 대칭
sns.histplot(data_normal, bins=30, kde=True, color='lightgreen', ax=axes[1])
axes[1].set_title("Symmetric")
axes[1].set_xlabel("Value")
axes[1].set_ylabel("Density")
axes[1].grid(True)
# 양의 왜도
sns.histplot(data_right, bins=30, kde=True, color='salmon', ax=axes[2])
axes[2].set_title("Positive Skew")
axes[2].set_xlabel("Value")
axes[2].set_ylabel("Density")
axes[2].grid(True)
plt.tight_layout()
plt.show()
첨도(Kurtosis)
분포의 뽀족함 또는 꼬리의 두꺼움 정도를 수치로 나타낸 값
- 정규 첨도: 정규분포처럼 적당히 뾰족하고 꼬리가 적당히 얇은 경우
- 고첨도: 중심에 데이터가 지나치게 몰려잇고 꼬리가 두꺼운 경우
- 저첨도: 분포가 평평하고 중앙 집중도가 낮은 경우
첨도의 종류
| 구분 | 첨도 값 (Fisher 기준) | 형태 | 설명 |
|---|---|---|---|
| 고첨도 | > 0 | 뾰족하고 꼬리가 두꺼움 | 이상치 발생 가능성이 높음 |
| 정규 첨도 | = 0 | 정규분포와 동일한 형태 | 기준값 (표준 정규분포) |
| 저첨도 | < 0 | 평평하고 중심 집중도 낮음 | 꼬리가 얇고 극단값이 드묾 |
from scipy.stats import kurtosis
np.random.seed(1)
# 고첨도: t-distribution (자유도 3)
data_high = np.random.standard_t(df=3, size=1000)
# 정규첨도
data_normal = np.random.normal(loc=0, scale=1, size=1000)
# 저첨도: uniform distribution
data_low = np.random.uniform(low=-3, high=3, size=1000)
# 첨도 출력
print("High kurtosis:", kurtosis(data_high))
print("Normal kurtosis:", kurtosis(data_normal))
print("Low kurtosis:", kurtosis(data_low))
# 시각화
fig, axes = plt.subplots(1, 3, figsize=(18, 5))
sns.histplot(data_high, bins=30, kde=True, color='orange', ax=axes[0])
axes[0].set_title("High Kurtosis")
axes[0].set_xlabel("Value")
axes[0].set_ylabel("Density")
axes[0].grid(True)
sns.histplot(data_normal, bins=30, kde=True, color='lightgreen', ax=axes[1])
axes[1].set_title("Normal Kurtosis")
axes[1].set_xlabel("Value")
axes[1].set_ylabel("Density")
axes[1].grid(True)
sns.histplot(data_low, bins=30, kde=True, color='skyblue', ax=axes[2])
axes[2].set_title("Low Kurtosis")
axes[2].set_xlabel("Value")
axes[2].set_ylabel("Density")
axes[2].grid(True)
plt.tight_layout()
plt.show()
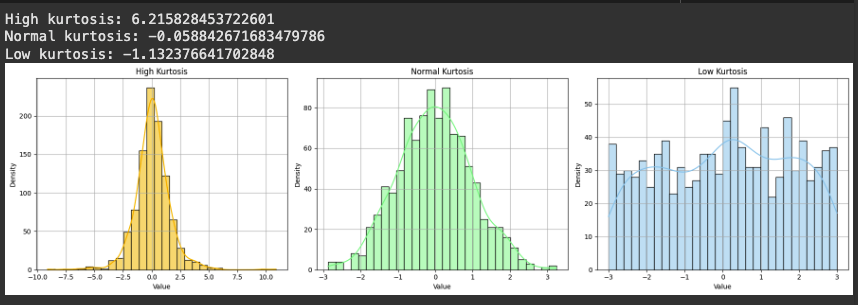
- 고첨도 분포에서 극단값(이상치) 자주 발생할 수 있음 > 예측 모델의 안정성에 영향을 줌
- 저첨도 분포는 데이터가 고르게 퍼져있어 중심 경향성만 보는 분석 한계 존재
- 첨도는 데이터의 위험성, 분포 특성, 모델 적합성을 평가할 때 중요한 지표가 됨