# 현재 환경을 저장하는 방법 > 버전, 패키지 명만 나옴
pip freeze > requirements.txt
# 로컬에서 진행하는 경우, 같은 환경에서 팀원들과 에러없이 진행하기 위해
# 상대의 환경을 내 로컬에 설치하는 방법
pip install -r requirements.txt
fromscipy.statsimportchi2_contingency# 변속기 타입(am)
am_count=df['am'].value_counts()# 범주/수치 상관없이 사용
# 실린더 수(cyl)
cyl_count=df['cyl'].value_counts().sort_index()# 범주/수치 상관없이 사용
# 교차표 만드는 메소드 > .crosstab
contingency_table=pd.crosstab(df['am'],df['cyl'],margins=True)# 합계 행렬 부분 삭제
observed=contingency_table.iloc[:-1,:-1]# 합계부분 제거 후 , 모델에 넣기 위한 사전 작업
observed=contingency_table.iloc[:-1,:-1].values# 카이제곱 검정을 통한 데이터 확인
chi2_stat,p_val,dof,expected=chi2_contingency(observed)print(chi2_stat)# 카이제곱
print(p_val)# p-value
print(dof)# 자유도
print(expected)# 기댓값
# 8.740732951259268
# 0.012646605046107276 > 0.05보다 작다 = 귀무가설 기각, 대립가설 채택
# 2
# [[6.53125 4.15625 8.3125 ]
# [4.46875 2.84375 5.6875 ]]
실린더 수(cyl)와 변속기 유형(am) 사이의 독립성 검정에서는:
H₀: 실린더 수와 변속기 유형은 서로 관련이 없다
H₁: 실린더 수와 변속기 유형은 서로 관련이 있다
적합성 검정(Goodness of Fit Test)
2.1 언제 적합성 검정을 사용하는가?
상황
예시 질문
실무 적용
균등성 검정
“모든 범주가 똑같이 나타나는가?”
주사위 공정성, 웹사이트 A/B 테스트 균등 배분
특정 비율 검정
“예상한 비율과 일치하는가?”
시장 점유율 예측 vs 실제, 유전자 비율 검정
이론 분포 검정
“특정 확률 분포를 따르는가?”
포아송 분포, 정규분포 적합성
2.2 검정 개념 및 가설
적합성 검정은 하나의 범주형 변수가 특정 이론적 분포와 일치하는지 검정
핵심 아이디어:
관측된 빈도 vs 기대되는 빈도 비교
χ² = Σ[(관측값 - 기대값)²/기대값]
가설 설정:
H₀: 관측 분포 = 기대 분포 (차이는 우연)
H₁: 관측 분포 ≠ 기대 분포 (체계적 차이 존재)
결과 해석 가이드:
p < 0.05: 기대 분포와 다르다 (H₀ 기각)
p ≥ 0.05: 기대 분포와 일치한다고 볼 수 있다 (H₀ 채택)
# 관측빈도
observed_cyl=df['cyl'].value_counts().sort_index()observed_cyl# 우리가 관측한 빈도는 11:7:14
# 기대빈도(이론상)
n_total=len(df)n_categories=len(observed_cyl)# 3개 의미
expected_equal=np.repeat(n_total/n_categories,n_categories)# 첫번째 인자를 두번째 인자만큼 반복 > 균등분포
# n_total / n_categories > 평균
print(n_total)print(n_categories)print(expected_equal)# 전체 카테고리합을 개수로 나눠서 균등하게 나눔(=균등분포표현)
# 32
# 3
# [10.66666667 10.66666667 10.66666667]
# 카이제곱 검정 실행
fromscipy.statsimportchi2_contingency,chisquare,fisher_exactchi2_stat,p_val=chisquare(f_obs=observed_cyl.values,f_exp=expected_equal)print(chi2_stat)print(p_val)# 2.3125
# 0.314663961018459 > 0.05보다 크다 > 귀무가설 채택 / 대립가설 기각
# => 기대분포와 일치
두 그룹만 비교한다면 t-test가 적합하지만, 여러 그룹을 t-test로 반복하면 1종 오류(α)가 급격히 늘어난다 → ANOVA로 한 번에 검정!
기본 가정
독립성 : 각 관측치는 서로 독립
정규성 : 각 그룹의 데이터 분포가 정규
등분산성 : 각 그룹의 분산이 동일
가정이 심하게 깨질 때는 Kruskal-Wallis 같은 비모수 검정이나 Welch-ANOVA(등분산 가정 완화)를 고려한다.
예시
# 데이터 로딩
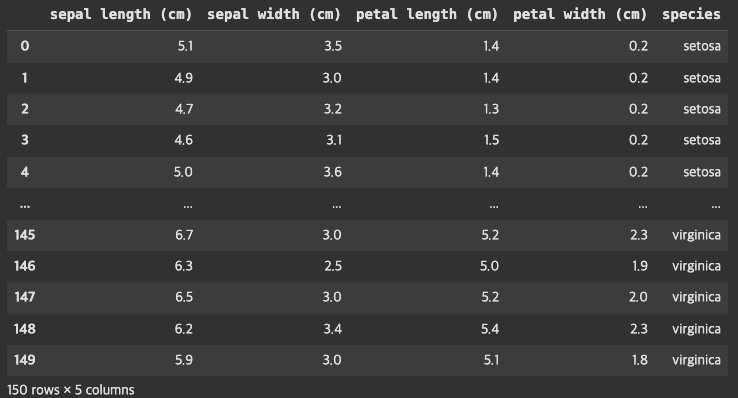
ris_data=load_iris()df=pd.DataFrame(iris_data.data,columns=iris_data.feature_names)df['species']=iris_data.target_names[iris_data.target]print("데이터셋 기본 정보:")print(f"샘플 수: {len(df)}")print(f"변수 수: {len(df.columns)-1}")print(f"품종: {df['species'].unique()}")# 데이터셋 기본 정보:
# 샘플 수: 150
# 변수 수: 4
# 품종: ['setosa' 'versicolor' 'virginica']
df
# 측정 변수들의 짧은 이름 정의
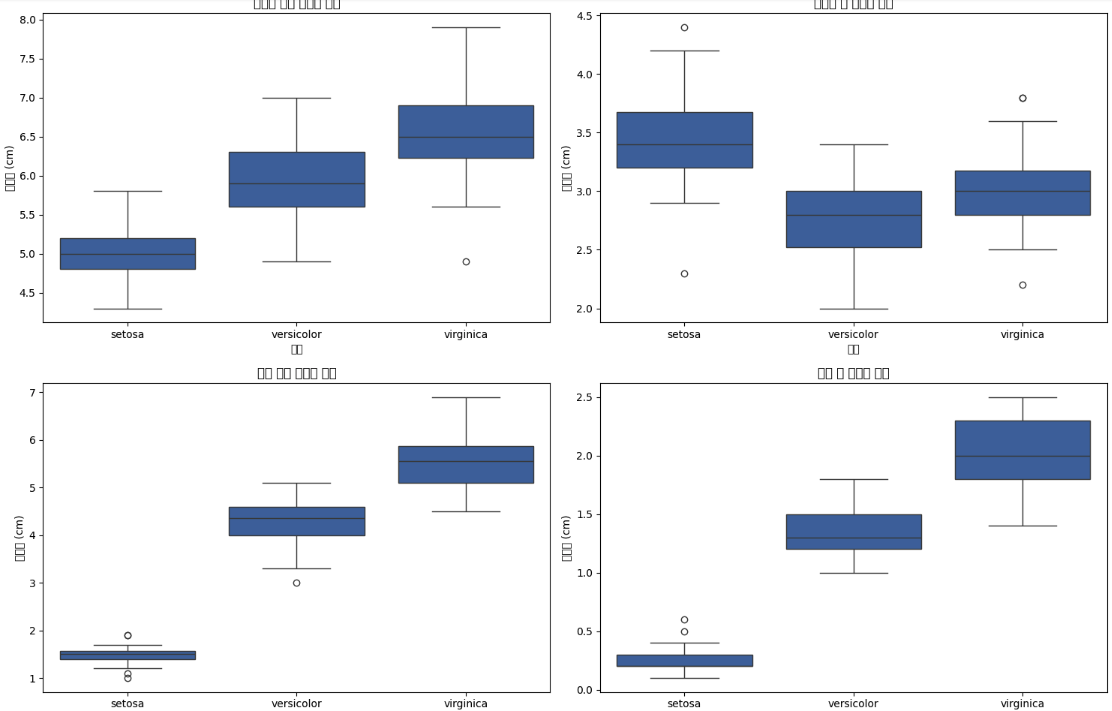
measurements=['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']short_names=['꽃받침 길이','꽃받침 폭','꽃잎 길이','꽃잎 폭']# 2x2 서브플롯으로 박스플롯 생성
fig,axes=plt.subplots(2,2,figsize=(15,10))axes=axes.ravel()fori,(measure,name)inenumerate(zip(measurements,short_names)):sns.boxplot(data=df,x='species',y=measure,ax=axes[i])axes[i].set_title(f'{name} 품종별 분포')axes[i].set_xlabel('품종')axes[i].set_ylabel('측정값 (cm)')plt.tight_layout()plt.show()
독립성 검정
실제 데이터테이블을 보고 데이터들이 다른 영역에 침법하고 있는지를 확인
즉, 수집된 샘플이 다른 개체에 영향을 주면 안된다.
정규성 검정
샤피로-윌크 검정(Shapiro-Wilk Test)은 주어진 데이터 샘플이 정규분포(Normal Distribution)를 따르는지 확인하기 위한 통계적 검정 방법
print("=== 정규성 검정 (Shapiro-Wilk Test) ===")print("H0: 데이터가 정규분포를 따른다")print("p > 0.05이면 정규성 가정 충족\n")formeasure,nameinzip(measurements,short_names):print(f"[{name}]")forspeciesindf['species'].unique():data=df[df['species']==species][measure]statistic,p_value=stats.shapiro(data)result="충족"ifp_value>0.05else"위반"print(f" {species}: p = {p_value:.4f} ({result})")print()
=== 정규성 검정 (Shapiro-Wilk Test) ===
H0: 데이터가 정규분포를 따른다
p > 0.05이면 정규성 가정 충족
[꽃받침 길이]
setosa: p = 0.4595 (충족)
versicolor: p = 0.4647 (충족)
virginica: p = 0.2583 (충족)
[꽃받침 폭]
setosa: p = 0.2715 (충족)
versicolor: p = 0.3380 (충족)
virginica: p = 0.1809 (충족)
[꽃잎 길이]
setosa: p = 0.0548 (충족)
versicolor: p = 0.1585 (충족)
virginica: p = 0.1098 (충족)
[꽃잎 폭]
setosa: p = 0.0000 (위반)
versicolor: p = 0.0273 (위반)
virginica: p = 0.0870 (충족)
등분산성 가정 검토
레빈 검정(Levene Test)은 두 개 이상의 집단(group)들의 분산이 서로 같은지 확인하는 통계적 방법으로 이를 분산의 동질성(homogeneity of variance)이라 한다.
print("=== 등분산성 검정 (Levene Test) ===")print("H0: 모든 집단의 분산이 같다")print("p > 0.05이면 등분산성 가정 충족\n")formeasure,nameinzip(measurements,short_names):# 각 품종별 데이터 분리
setosa_data=df[df['species']=='setosa'][measure]versicolor_data=df[df['species']=='versicolor'][measure]virginica_data=df[df['species']=='virginica'][measure]# Levene 검정
statistic,p_value=stats.levene(setosa_data,versicolor_data,virginica_data)result="충족"ifp_value>0.05else"위반"print(f"{name}: F = {statistic:.4f}, p = {p_value:.4f} ({result})")
=== 등분산성 검정 (Levene Test) ===
H0: 모든 집단의 분산이 같다
p > 0.05이면 등분산성 가정 충족
꽃받침 길이: F = 6.3527, p = 0.0023 (위반)
꽃받침 폭: F = 0.5902, p = 0.5555 (충족)
꽃잎 길이: F = 19.4803, p = 0.0000 (위반)
꽃잎 폭: F = 19.8924, p = 0.0000 (위반)
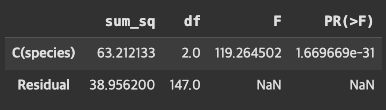
importstatsmodels.apiassmfromstatsmodels.formula.apiimportols# 선형회귀 분석 ols
# Q("sepal length (cm)" 변수 하나를 넣고, 모델 훈련시키고
model=ols('Q("sepal length (cm)") ~ C(species)',data=df).fit()# residual > 잔차를 계산한것, F > F 통계량 값
anova_table=sm.stats.anova_lm(model,typ=2)anova_table
사후검정(Post-hoc test)
사후 검정은 분산분석(ANOVA)에서 “집단 간 차이가 있다”는 결과를 얻은 후, 구체적으로 어떤 집단들 사이에 유의미한 차이가 있는지 알아보기 위해 수행하는 추가 분석
t 검정은 모집단의 분산을 모르고 표본 크기가 작을 때(일반적으로 30개 미만) 사용하는 검정 방법으로 정규분포 대신 t분포를 사용하여 검정을 수행한다.
t 검정의 종류
단일표본 t 검정 (One-sample t-test)
하나의 표본 평균이 특정 값(모집단 평균)과 차이가 있는지 검정
예: 우리 학교 학생들의 평균 키가 전국 평균 170cm와 다른가?
독립표본 t 검정 (Independent samples t-test)
서로 독립적인 두 집단의 평균 차이를 검정
예: 남학생과 여학생의 수학 점수에 차이가 있는가?
대응표본 t 검정 (Paired samples t-test)
동일한 대상에서 두 번 측정한 값의 차이를 검정
예: 다이어트 프로그램 전후의 체중 변화가 있는가?
기본 가정사항
t 검정을 사용하기 위해서는 다음 조건들이 충족되어야 함
정규성: 데이터가 정규분포를 따라야 함
독립성: 각 관측치는 서로 독립적이어야 함
등분산성: 두 집단을 비교할 때 분산이 비슷해야 함(독립표본 t 검정의 경우)
t 통계량 계산
t 통계량은 다음과 같이 계산된다
t = (표본평균 - 모집단평균) / (표준오차)
이 값을 t분포표와 비교하여 p-value를 구하고
유의수준(보통 0.05)과 비교하여 귀무가설의 기각 여부를 결정
0.05 이하: 귀무가설 기각, 대립가설 채택
0.05 이상: 귀무가설 채택, 대립가설 기각
주의사항
표본 크기가 큰 경우(n>30)에는 z 검정을 사용할 수도 있음
정규성 가정이 심하게 위배되면 비모수 검정(Mann-Whitney U test, Wilcoxon signed-rank test)을 고려
다중 비교 시에는 제1종 오류를 조정해야 함
1종오류: 귀무가설이 사실인데, 거젓이라고 결정
2종오류: 귀무가설이 거짓인데, 사실이라고 결정
t 검정은 통계학에서 가장 기본적이면서도 널리 사용되는 검정 방법으로, 연구 설계와 데이터 특성에 맞는 적절한 t 검정을 선택하는 것이 중요하다.
# 통계 라이브러리 import
fromscipyimportstatsfromstatsmodels.formula.apiimportols,glm# 와인의 퀄리티 확인
red_wine=wine.loc[wine['type']=='red','quality']white_wine=wine.loc[wine['type']=='white','quality']white_wine
# t-test 함수에 red_wine,white_wine 를 x값으로써 집어 넣는다
stats.ttest_ind(red_wine,white_wine)

 지혜의 개발공부로그
지혜의 개발공부로그