지혜의 개발공부로그
지혜의 개발공부로그
Pandas 시계열 다루기
30 Jul 2025 | DA개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
시계열 데이터
일정 시간 간격으로 어떤 값을 기록한 데이터
시계열 데이터 만들어보기
data = {
'Date1': ['2024-02-17', '2024-02-18', '2024-02-19', '2024-02-20'],
'Date2': ['2024:02:17', '2024:02:18', '2024:02:19', '2024:02:20'],
'Date3': ['24/02/17', '24/02/18', '24/02/19', '24/02/20'],
'Date4': ['02/17/2024', '02/18/2024', '02/19/2024', '02/20/2024'],
'Date5': ['17-Feb-2024', '18-Feb-2024', '19-Feb-2024', '20-Feb-2024'],
'DateTime1': ['24-02-17 13:45:30', '24-02-18 14:55:45', '24-02-19 15:30:15', '24-02-20 16:10:50'],
'DateTime2': ['2024-02-17 13-45-30', '2024-02-18 14-55-45', '2024-02-19 15-30-15', '2024-02-20 16-10-50'],
'DateTime3': ['02/17/2024 01:45:30 PM', '02/18/2024 02:55:45 PM', '02/19/2024 03:30:15 AM', '02/20/2024 04:10:50 AM'],
'DateTime4': ['17 Feb 2024 13:45:30', '18 Feb 2024 14:55:45', '19 Feb 2024 15:30:15', '20 Feb 2024 16:10:50']
}
df = df.DataFrame(data)
df

df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date1 4 non-null object
1 Date2 4 non-null object
2 Date3 4 non-null object
3 Date4 4 non-null object
4 Date5 4 non-null object
5 DateTime1 4 non-null object
6 DateTime2 4 non-null object
7 DateTime3 4 non-null object
8 DateTime4 4 non-null object
dtypes: object(9)
memory usage: 420.0+ bytes
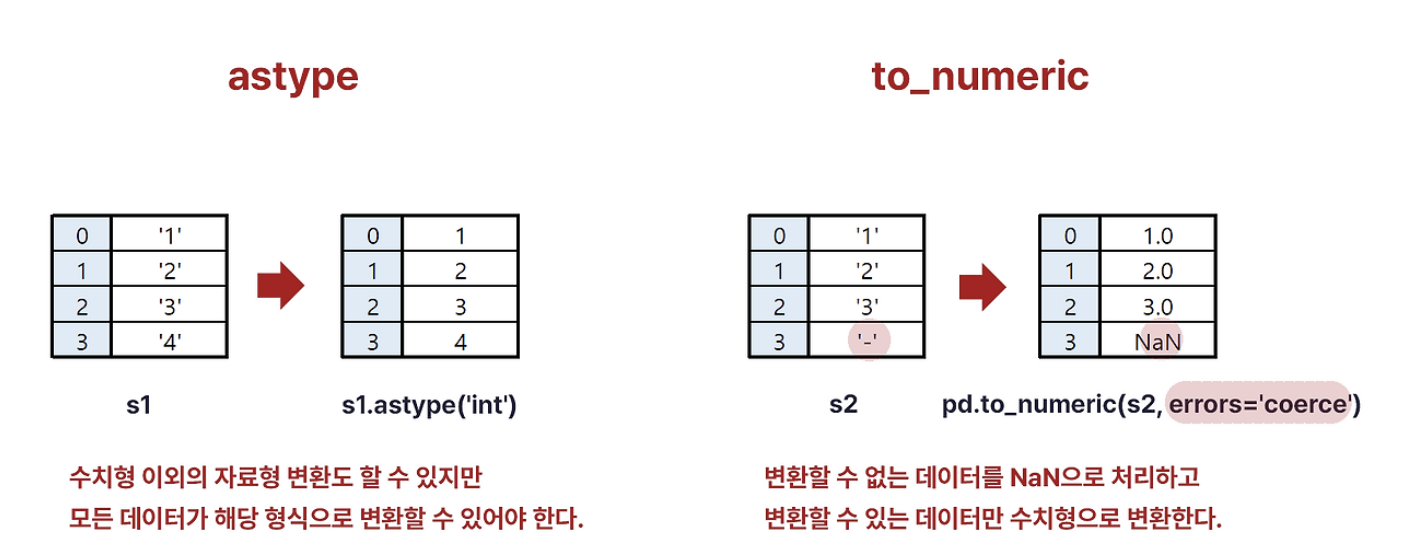
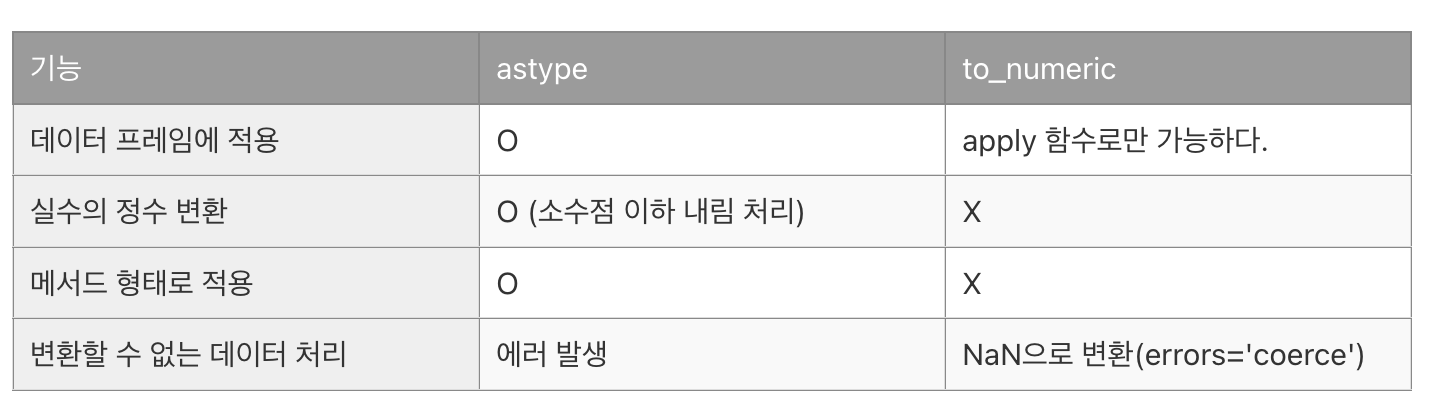
모든 데이터가 object형인것을 볼 수 있다. 우선 Date1을 datetime형으로 변환해보자.
df['Date1'] = pd.to_datetime(['Date1'])
그런데 이때, Date2, Date3, DateTime1, DateTime2도 위와 같이 변환이 가능할까?
아니다. 오류가 뜬다.
DateParseError: hour must be in 0..23: 2024:02:17, at position 0
pd.to_datetime으로 인식할 수 있는 포맷이 아니기 때문이다. 이런때에는 format함수를 통해 형식에 맞게 포맷팅해주는 것이 중요하다. 이때는 파이썬에서 지원하는 %y, %m, %d등을 사용해 변환해주면 된다.
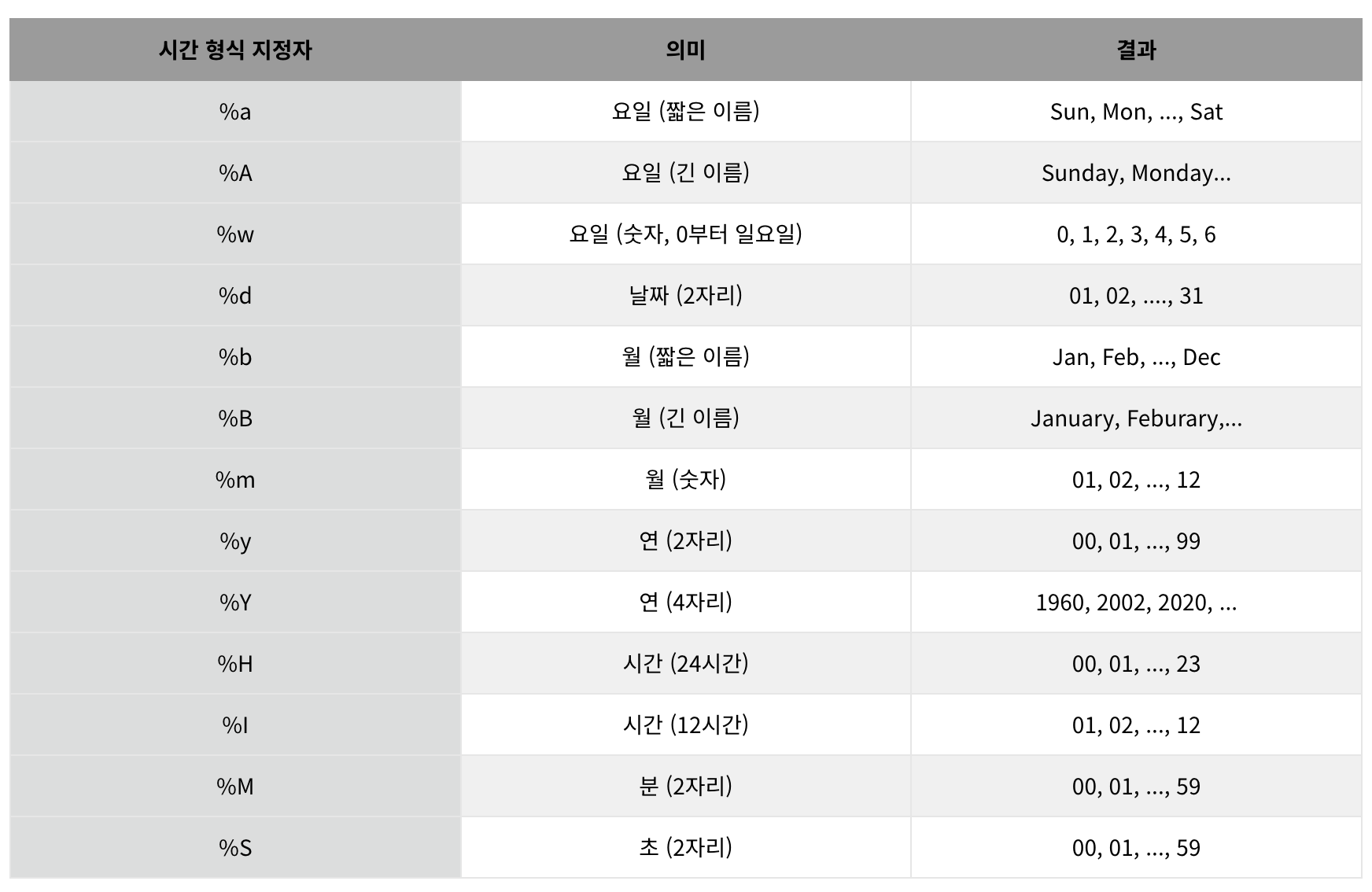
df['Date2'] = pd.to_datetime(df['Date2'], format = '%Y:%m:%d')
df['Date3'] = pd.to_datetime(df['Date3'] ,format = '%y/%m/%d' )
df['Date4'] = pd.to_datetime(df['Date4'] )
df['Date5'] = pd.to_datetime(df['Date5'] )
df['DateTime1'] = pd.to_datetime(df['DateTime1'], format = '%y-%m-%d %H:%M:%S')
df['DateTime2'] = pd.to_datetime(df['DateTime2'], format = '%Y-%m-%d %H-%M-%S')
df['DateTime3'] = pd.to_datetime(df['DateTime3'])
df['DateTime4'] = pd.to_datetime(df['DateTime4'])
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date1 4 non-null datetime64[ns]
1 Date2 4 non-null datetime64[ns]
2 Date3 4 non-null datetime64[ns]
3 Date4 4 non-null datetime64[ns]
4 Date5 4 non-null datetime64[ns]
5 DateTime1 4 non-null datetime64[ns]
6 DateTime2 4 non-null datetime64[ns]
7 DateTime3 4 non-null datetime64[ns]
8 DateTime4 4 non-null datetime64[ns]
dtypes: datetime64[ns](9)
memory usage: 420.0 bytes
완변하게 모든 데이터가 datetime으로 형변환이 되었다.
df = df[['Date1','Date2','Date3','Date4','Date5','DateTime1','DateTime2','DateTime3','DateTime4']]
위 데이터 중 Date1의 년,월,일,시,분,초,분기,요일을 나타내는 방법은 아래와 같다.
df['year'] = df['Date1'].dt.year
df['month'] = df['Date1'].dt.month
df['day'] = df['Date1'].dt.day
df['hour'] = df['Date1'].dt.hour
df['minute'] = df['Date1'].dt.minute
df['second'] = df['Date1'].dt.second
df['quarter'] = df['Date1'].dt.quarter
or
df['quarter'] = df['Date1'].dt.to_period('Q')
df['week'] = df['Date1'].dt.dayofweek
시계열 연산
datetime으로 변환한 데이터는 연산이 가능하다.
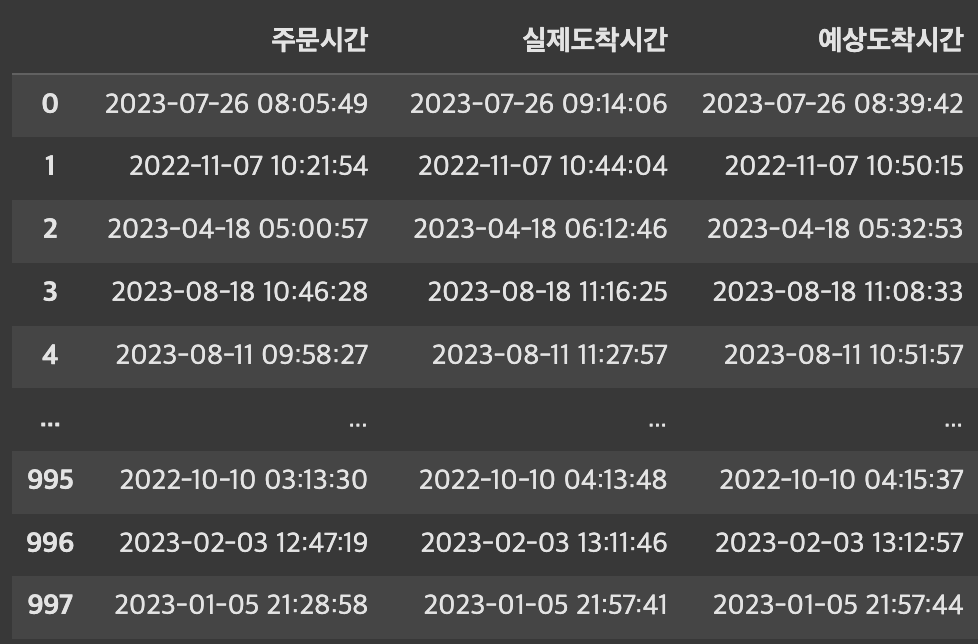
# 예상 도착시간보다 늦게 도착한 경우
df_time_diff = df['예상도착시간'] - df['실제도착시간']