자료구조는 개발자가 데이터를 효율적으로 사용할 수 있도록 정리하는 방법을 말한다. 각각의 자료구조에는 장단점이 있기에 어떤 자료구조가 최선일지는 해결하고자 하는 문제의 종류와 어떤 부분을 우선적으로 최적화할지에 따라 달라질 수 있다. 따라서 다양한 자료구조의 장단점을 살펴보며 어플리케이션의 특징에 따라 어떤 자료구조를 사용하는 것이 최선일지 판단하는 것이 중요하다.
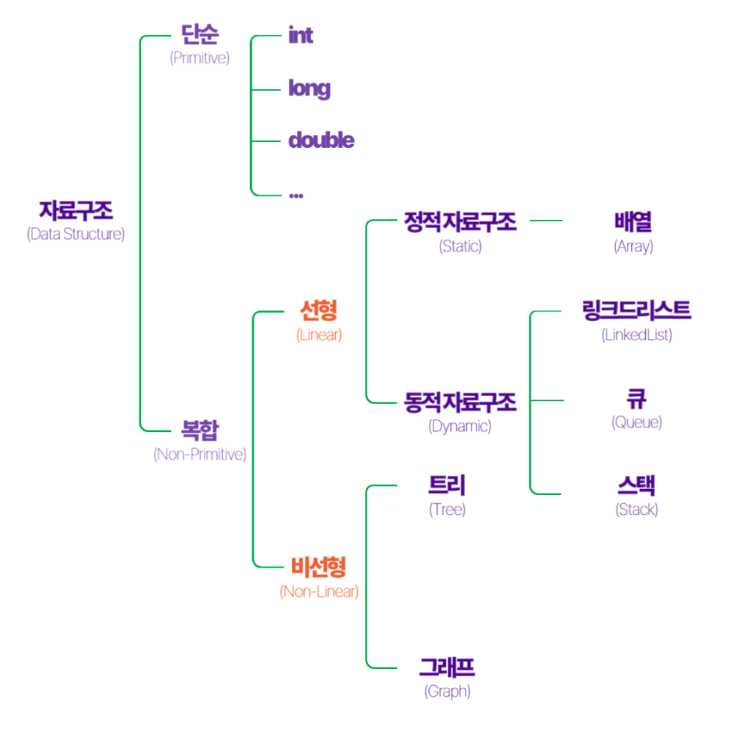
자료구조는 선형과 비선형 등의 여러 속성을 기반으로 분류 가능하다.
선형 자료구조(Linear Data Structure) > 데이터 요소를 순서대로 정렬
정적 자료구조(Static Data Structure): 크기가 고정되어 있는 자료구조
동적 자료구조(Dynamic Data Structure): 크기가 바뀔 수 있는 자료구조
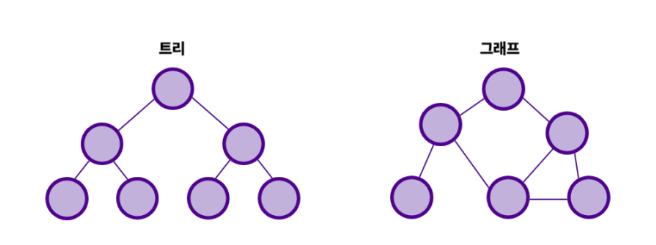
비선형 자료구조(Nonlinear Data Structure) > 데이터를 비연속적으로 연결
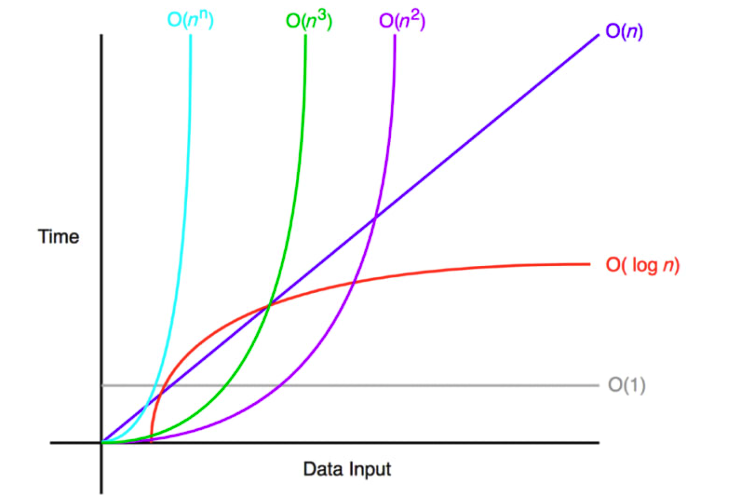
자료구조를 순회한다는 말은 자료구조의 첫번쨰 요소에서 마지막 요소로 이동한다는 것을 의미한다. 선형 자료구조에서는 첫번쨰 요소에서 마지막 요소까지 백트래킹(BackTracking)없이 쉽게 순회가 가능하지만, 비선형 자료구조에서는 종종 되돌아가야 한다.
비선형 자료구조에서는 원하는 요소에 접근하기 위해 백트래킹이나 재귀가 필요한 경우가 많기 때문에 개별요소에 접근하는 작업에는 선형자료구조가 더 효율적이다. 또한 선형 자료구조는 데이터를 쉽게 순회할 수 있어 비선형 자료구조에 비해 요소 전체를 변경하는 작업이 쉽고, 백트래킹 없이 모든 요소에 접근할 수 있어 자료구조를 설계하고 사용하는 것도 더 쉽다. 그치만 비선형 자료구조는 소셜네트워크 연결과 같은 데이터를 저장하기에 선형 자료구조보다 더 효율적이기 때문에 각각의 특징에 따라 알맞은 자료구조를 선택하는 것이 중요하다.
선형 자료구조
데이터의 요소가 순차적 혹은 선형으로 배열되고 일대일 관계에 있으며 각 요소가 이전 및 다음 인접 요소에 연결되는 자료구조
이러한 선형 자료구조에는 정적/동적 자료구조로 구분되어진다.
정적 자료구조: 크기가 고정되어있는 자료구조. 대표적인 예로 배열이 있다. 선언과 동시에 배열의 크기가 정해지고 이후에는 그 크기가 변경 불가능하다. 미리 할당된 메모리 공간에 데이터를 저장하기 때문에 데이터의 추가, 삭제, 크기 변경등이 제한적인 것이 특징이다.
동적 자료구조: 크기가 동적으로 저정될 수 있는 자료구조. 대표적인 예로 ArrayList, Linked List, Queue, Stack이 있다. 필요에 따라 메모리에서 유연하게 공간을 할당하고 해제해 데이터를 저장할 수 있어 데이터의 추가, 삭제, 크기 변경등이 가능하다.
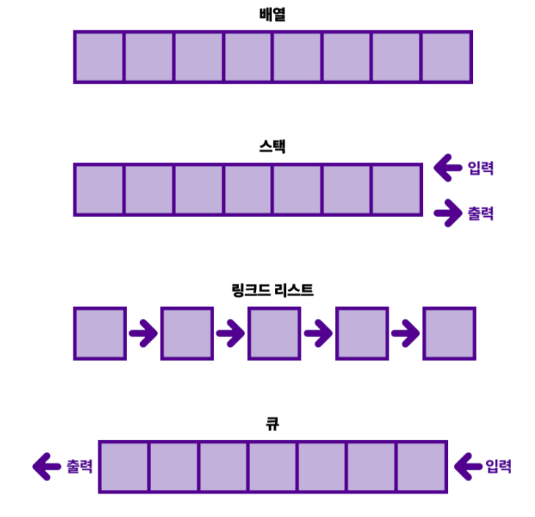
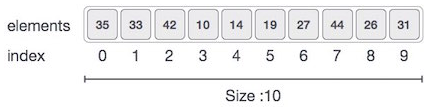
배열(Array)
인덱스를 사용해 배열의 각 요소를 쉽게 식별할 수 있는 인덱스 기반 데이터 구조를 사용
동일한 데이터 유형의 여러값을 저장하려는 경우 효율적으로 활용이 가능하다. 각 요소의 인덱스 접근이 용이!
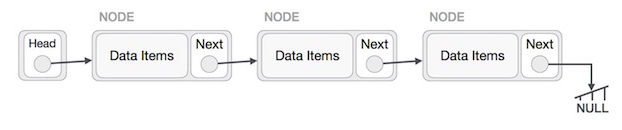
연결 리스트(Linked List)
각 요소가 인접한 메모리 위치에 저장되지 않는 선형 자료구조로 포인터로 연결되는 것이 특징.
자료가 추가될 때마다 메모리를 할당받고, 자료는 링크=주소로 연결된다. 자료의 물리적 위치와 논리적 위치가 다를 수 있다. 첫번째 노드는 Head, 마지막 노드의 다음 포인터는 항상 null이다. 따라서 각 노드는 다음 노드의 주소만 포함하고 있기 떄문에 인덱스를 통한 접근은 불가능하다. (비연속성)
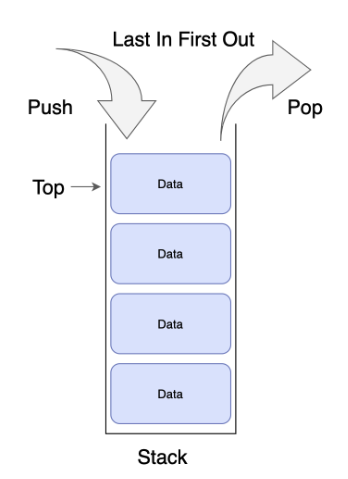
스택(Stack)
작업이 수행되는 특정 순서를 따르는 선형자료구조 > LIFO(Last In First Out)으로 마지막에 쌓인 데이터가 먼저 나오는 후입선출 방식이다. 데이터 입력 및 검색은 한쪽 끝에서만 가능하고 데이터 입력은 push(), 삭제는 pop()으로 이루어진다.
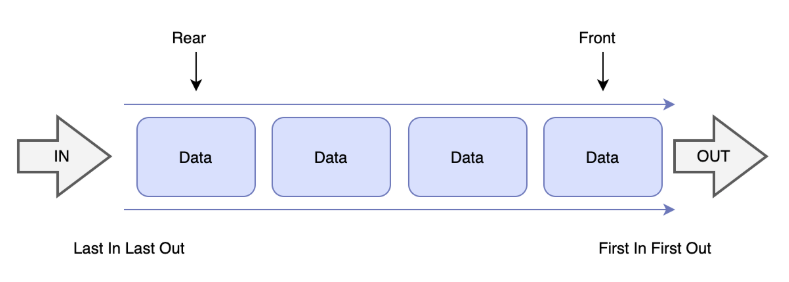
큐(Queue)
스택과 마찬가지로 작업이 수행되는 특정 순서를 따르는 선형자료구조 > FIFO(First In First Out)으로 처음 들어온 데이터가 먼저 나오는 선입선출 방식이다. 큐의 마지막 요소를 제거하기 위해서는 큐 안의 모든 요소를 제거해야만 가능하다.
# 데이터프레임에 전달할 딕셔너리 생성
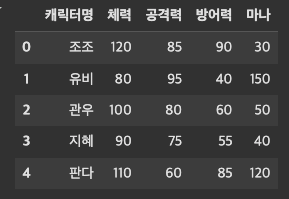
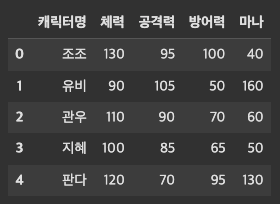
characters={'캐릭터명':['조조','유비','관우','지혜','판다'],'체력':[120,80,100,90,110],'공격력':[85,95,80,75,60],'방어력':[90,40,60,55,85],'마나':[30,150,50,40,120]}# 일반적
df_character=pd.DataFrame(character)# 인덱스를 지정해주는 경우 > column을 추가하는데, 어떤것을 인덱스로 설정할지 지정
df_character=pd.DataFrame(character,index=[*])
이렇게 만들어준 딕셔너리(character)를 데이터프레임으로 만들면 아래와 같이 생성이 된다.
DataFrame에서의 copy()힘수는 얕은 복사임에도 깊은 복사 효과를 볼 수 있다고 한다. 즉 copy()함수를 사용하더라도 원본에 영향을 주지는 않는다는 것.이는 pandas만의 특징이라고 하는데, 이를 통해 메모리를 적게 차지하여 메모리 효율성을 높일 수 있다. (깊은 복사하는 방법: .copy(deep=True))
이렇게 만든 데이터프레임으로 무얼 할수 있는지 봐보자
인덱싱과 슬라이싱
수천 수만개의 데이터를 다루다보면 원하는 데이터만 쏙쏙 뽑아 보고싶어질 것이다. 이때 사용하는 것이 인덱싱, 슬라이싱이다.
# 1. column(열)을 직정 지정해 뽑아내는 방법
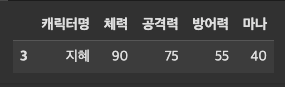
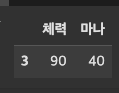
cols=['체력','공격력']df_character[cols]# 이때 행에 대한 인덱싱은 불가능하다. > df_character[1] 이런건 불가능
# 아마도 행은 key값이니까 딕셔너리의 key값을 뽑아내는 방식을 떠올려보면 될듯!
# 2. row(행)을 지정해 뽑아내는 방법
df_character[:2]# 3. 행과 열을 뽑아내는 방법
df_character[cols][:2]
loc, iloc
loc: 라벨 기반의 인덱싱. 즉 행 또는 열의 이름을 이용해 특정 위치의 행과 열에 접근이 가능하다.
iloc: 정수 기반의 인덱싱. 즉 정수 인덱스를 이용해 특정 위치의 행과 열에 접근이 가능하디.
일반적으로 데이터 처리 시 필요한 데이터 세트는 2차원 데이터로 구성되며, (데이터 정리 분석, 모델링, 분석결과 또는) 표 형식으로 표시하기에 적합한 형식으로 구성된다. 2차원 데이터는 행렬로 이루어져 있기 때문에 이해하기 쉬운 구조이며, 효과적으로 데이터를 담을 수 있기 때문이다.
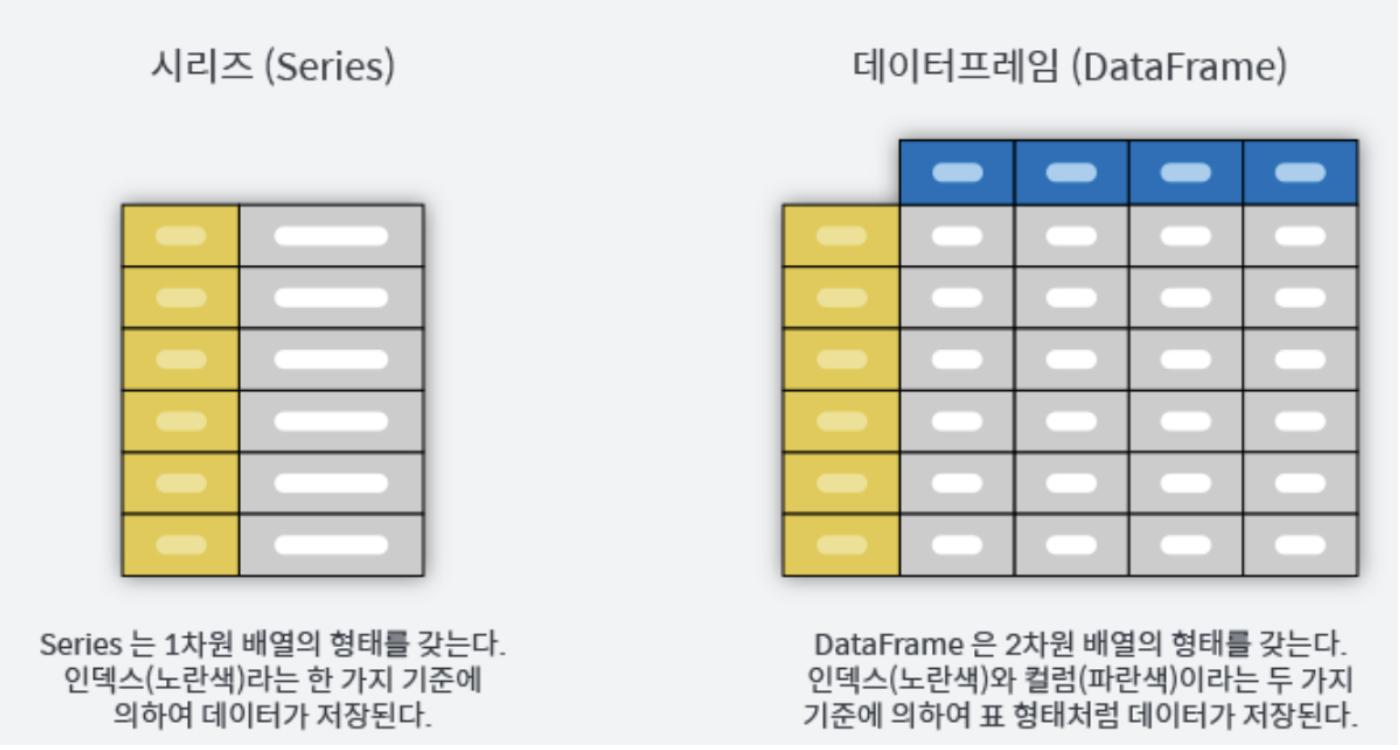
Series와 DataFrame
우선 Series와 DataFrame 모두 pandas의 데이터 오브젝트이다. 아래 사진을 보면 이해가 더욱 쉬워진다.
우선 Series는 인덱스와 값으로 이루어진 열이 하나인 자료형이다. 그렇다면 DataFrame은 어떻게 구성되어있을까? 칼럼 단위의 시리즈 모음과 인덱스로 구성이 되어있다.
즉, DataFrame은 행과 열의 인덱스가 존재하고 이 인덱스에 맞게 데이터들이 존재하는 데이터구조를 의미한다. 이를 직접 만들수도 있고, 엑셀이나 csv 파일을 읽어와 만들기도 한다.
번외로 데이터프레임을 만드는 형식은 늘 딕셔너리인가? 궁금했었는데..
딕셔너리가 아닌 리스트, 넘파이 등등 다양한 방법으로도 데이터프레임을 만든다고는 한다. 하지만 이는 실무에서 너무 복잡한 형태여서 거의 사용하지는 않는다고..! 대체로 데이터프레임은 딕셔너리로 생성하고 이때의 key값이 컬럼명, value값이 각 데이터 값(열)에 들어가는 것!
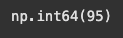
이처럼 np.sort(배열명)의 경우에는 복사한 값에 새롭게 정렬된 배열이 할당되지만(arr_sort1) 기존 arr1의 배열에는 아무런 변화가 없음을 알 수 있다. 그러나 np.sort()의 경우에는 기존 arr1의 값이 변하는 것을 볼 수 있다. 다만 arr_sort2에서 반환되는 값은 None이다.
내림차순 하는 방법은 아래와 같다.
arr_re_sort=np.sort(arr1)[::-1]# [7,5,3,1]
그러면 argsort()는 어떻게 쓸까?
arr1=np.argsort([3,1,7,5])arr1# > ([1, 0, 3, 2])
이렇듯 정렬된 값의 기존 인덱스 값을 배열에 반환하는 것을 볼 수 있다.
arr1=np.argsort([3,1,7,5])#[1,3,5,7] 로 소팅된 후 기존 [3,1,7,5]일때의 인덱스 값을 반환
arr1# > ([1, 0, 3, 2])
그렇다면 이것도 내림차순이 가능할까? 가능함!
arr1=np.argsort([3,1,7,5])[::-1]# [7,5,3,1]로 역순 소팅 후 기존 [3,1,7,5]일때의 인덱스 값 반환
arr1# > ([2, 3, 0, 1])

 지혜의 개발공부로그
지혜의 개발공부로그