지혜의 개발공부로그
지혜의 개발공부로그
자료구조, Queue
16 Jul 2025 | Data Structure개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
Queue
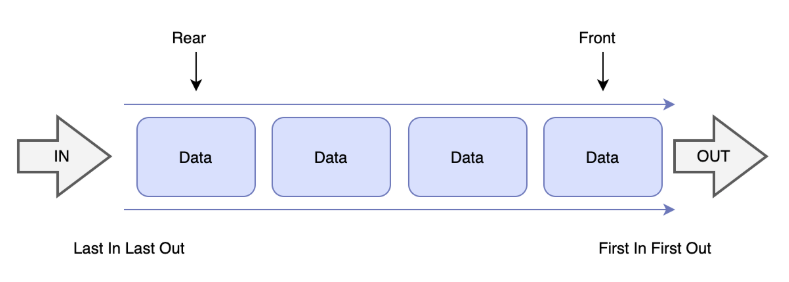
선형 자료구조 중에서도 동적 자료구조에 해당하는 Queue는 필요에 따라 메모리에 공간을 유연하게 할당하고 해제해 데이터를 저장할 수 있어 데이터의 추가, 삭제, 크기 변경등이 가능하다. 이때 스택의 가장 중요한 특징은 FIFO 개념이다.
FIFO: First In First Out
- 먼저 들어온 데이터가 먼저 나가는 자료구조
- 선착순의 원리 > 먼저 들어온 사람이 먼저 서비스를 받음
- 스택과 반대되는 개념
주요 연산
- Enqueue(인큐): queue의 뒤쪽(rear) 데이터에 삽입
- Dequeue(디큐): queue의 앞쪽(front) 데이터 삭제 및 반환
Python으로 구현해보는 queue
class Queue:
def __init__(self):
# queue를 담아줄 빈 리스트 생성
self.items = []
# 맨 앞의 인덱스 0 지정
self.front_index = 0
def enqueue(self, value):
# items안에는 일단 차곡차곡 데이터가 쌓인다
self.items.append(value)
def dequeue(self):
try:
# items이 빈리스트가 아니라면 (값이 있다면)
return self.items.pop(0)
except IndexError:
# items에 아무것도 없다면 더이상 삭제할 아이템이 없으니까 indexError발생
print('Queue is empty')
return None
queue = Queue()
queue.enqueue(3)
queue.enqueue(23)
queue.enqueue(5345)
queue.enqueue(234)
queue.enqueue(5456)
queue.items
# 출력: [3, 23, 5345, 234, 5456]
queue.dequeue()
# 출력: 3
stack.items
# 출력: [23, 5345, 234, 5456]
각 연산들의 시간 복잡도: O(1) 인 것도 확인 가능하다. (enqueue, dequeue)
- Enqueue
- 리스트의 append 함수 사용
- 항상 리스트의 끝에 데이터가 추가됨
- Dequeue
- 리스트의 pop 함수 사용
- 항상 리스트의 맨 앞 데이터가 삭제됨
- collections의 deque를 사용해도 됨
큐 예제 > 조세푸스(josephus)
- 문제 상황
- N명이 원형으로 앉아있음
- K번째 사람마다 제거
- 마지막 남은 1명의 번호 찾기
case1, 그냥 풀어보기
def josephus(n, k):
queue_list = []
for i in range(1, n+1):
# 1부터 n까지 큐에 enqueue
queue_list.append(i)
# 2. 반복:
# - (k-1)개는 dequeue 후 다시 enqueue
# - k번째는 dequeue만 (제거)
# 3. 큐에 1개만 남을 때까지 반복
while len(queue_list) > 1:
for i in range(k-1):
queue_list.append(queue_list.pop(0))
queue_list.pop(0)
# 4. 마지막 남은 번호 반환
return queue_list
josephus(6,2)
case2, deque 활용해서 풀어보기
from collections import deque
# deque 사용해보기
def josephus(n, k):
dq = deque()
for i in range(1, n+1):
# 1부터 n까지 큐에 enqueue
dq.append(i)
# 2. 반복:
# - (k-1)개는 dequeue 후 다시 enqueue > k-1: 앞에서 몇번 건너뛸지
# - k번째는 dequeue만 (제거)
# 3. 큐에 1개만 남을 때까지 반복
while len(dq) > 1:
for i in range(k-1):
dq.append(dq.popleft())
dq.popleft()
# 4. 마지막 남은 번호 반환
return dq
josephus(6,2)