
 지혜의 개발공부로그
지혜의 개발공부로그
SQL 함수 사용하기 (집계함수)
23 Jul 2025 | SQL개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
집계 함수
여러 행에 걸쳐 있는 값을 묶어서 계산을 수행하여 단일 값을 반환하는 함수
- COUNT(): 레코드의 개수 계산
- SUM(): 합
- AVG(): 평균
- MAX(): 최대값
- MIN(): 최소값
- STDDEV(): 표준편차
집계함수의 활용 1. WHERE절
WHERE 절에 조건을 넣으면 조건에 맞는 레코드에 한해 값을 요약
-- 고객테이블에서 '서울특별시' 고객에 대해 마일리지합, 평균, 최소, 최대값을 조회
SELECT SUM(마일리지), AVG(마일리지), MIN(마일리지), MAX(마일리지) FROM 고객 WHERE 도시 = '서울특별시';
집계함수의 활용 2. GROUP BY절
그룹별로 묶어서 요약할 때 사용
- SELECT 절에 그룹으로 묶을 컬럼명과 집계함수를 넣음
- SELECT 절의 집계함수를 제외한 나머지 컬럼이나 수식은 반드시 GROUP BY 절에 넣어야 오류발생이 없음
-- 문제1: 고객 테이블에서 도시별 고객의 수와 해당 도시 고객들의 마일리지 평균을 구하시오
SELECT 도시, COUNT(*), AVG(마일리지) FROM 고객
GROUP BY 1;
-- 문제2: 위 문제에서 중복된 도시를 제거한 데이터를 구하시오
SELECT DISTINCT 도시, COUNT(*), AVG(마일리지) FROM 고객
GROUP BY 1;
-- 문제3: 담당자직위별로 묶고, 같은 담당자직위에 대해서는 도시별로 묶어 집계한 결과
-- 고객수와 평균 마일리지를 보이시오. 이떄 담당자직위, 도시순으로 정렬하기
SELECT 담당자직위, 도시, COUNT(*) 고객수, AVG(마일리지) AS '평균 마일리지' FROM 고객
GROUP BY 1,2
ORDER BY 1,2
집계함수의 활용 3. HAVING 절
GROUP BY 결과에 대해 추가 조건을 넣고자 할 때 사용\n 이때 SELECT 절에 있는 컬럼과 함수에 대한 조건만 넣을 수 있다!
-- 문제1: 고객 테이블에서 도시별로 그룹을 묶어 고객수와 평균마일리지를 구하고,
-- 이중에서 고객수가 10명 이상인 레코드만 걸러내시오
SELECT 도시, COUNT(*) 고객수, AVG(마일리지) FROM 고객
GROUP BY 1
HAVING 고객수 >= 10;
-- 문제2: 고객번호가 T로 시작하는 고객에 대해 도시별로 묶어서 고객의 마일리지를 구하시오
-- 이떄 마일리지의 합이 1000점 이상인 레코드만 보이시오
SELECT 도시, SUM(마일리지) FROM 고객
WHERE 고객번호 LIKE 'T%'
GROUP BY 1
HAVING SUM(마일리지) >= 1000;
집계함수 심화 1. WITH ROLLUP
그룹별 소계와 전체 총계를 한번에 확인하고 싶을 떄 사용\n GROUP BY 절 다음에 WITH ROLLUP을 붙여 사용
-- 문제1: 지역이 null인 고객에 대해 도시별 고객수, 평균 마일리지를 보이시오
-- 이때 마지막 행에 전체 고객수와 전체 고객에 대한 평균 마일리지도 함께 보이시오
SELECT 도시, COUNT(*), AVG(마일리지) FROM 고객
WHERE 지역 IS NULL
GROUP BY 1 WITH ROLLUP;
-- 문제2: 담당자직위에 마케팅이 들어가있는 고객에 대해 도시별 고객수, 평균 마일리지를 보이시오
-- 담당자직위별 고객수와 전체 고객수도 함꼐 볼수 있도록 조회
SELECT 담당자직위, 도시, COUNT(*), AVG(마일리지) FROM 고객
WHERE 담당자직위 LIKE '%마케팅%'
GROUP BY 1,2 WITH ROLLUP;
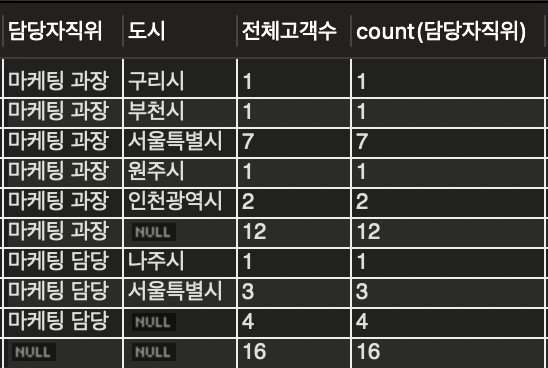
이렇게 마케팅 과장에 대한 고객수 합, 마일리지 평균 & 마케팅 담당에 대한 고객수 합, 마일리지 평균이 총계로 나와있는 것을 확인할 수 있다.
집계함수 심화 2. GROUPING
WITH ROLLUP 결과로 나온 NULL에 대해 1을 반환하고, 그렇지 않으면 0을 반환
-- 문제: 담당자직위가 대표 이사인 고객에 대해 지역별로 묶어 고객수를 보이고 전체고객수를 같이 보이시오
SELECT 지역, COUNT(*) FROM 고객
WHERE 담당자직위 = '대표 이사'
GROUP BY 1 WITH ROLLUP;

이때 결과의 맨위 null은 실제 진짜 데이터상 존재하는 null의 합이고 마지막 null은 WITH ROLLUP을 통해 나온 총계를 의미한다. 이렇듯 각각의 NULL을 구분하기 위해 사용하는 것이 GROUPING이다.
SELECT 지역, COUNT(*), GROUPING(지역) FROM 고객
WHERE 담당자직위 = '대표 이사'
GROUP BY 1 WITH ROLLUP;

이렇게 WITH ROLLUP에 결과로 나온 null 값에는 1, 그렇지 않은 곳에는 0이 적혀있는 것을 볼 수 있다.
집계함수 심화 3. GROUP_CONCAT()
각 행의 값을 결합
-- 문제1: 사원테이블에 있는 이름을 한 행에 나열하시오
SELECT GROUP_CONCAT(이름) FROM 사원;
-- 문제2: 고객테이블에 들어있는 지역을 한행에 나열하되 중복되는 지역은 한번만 보이시오
SELECT GROUP_CONCAT(distinct 지역) FROM 고객;
-- 문제3: 고객테이블에서 도시별로 고객회사명을 나열하시오
SELECT 도시, GROUP_CONCAT(고객회사명) FROM 고객
GROUP BY 도시;
문제를 풀어보자
문제1
주문테이블에서 요청일보다 발송이 늦어진 주문내역이 월별로 몇건씩인지 요약하시오. 이때 주문월 순서대로 정렬하시오
SELECT MONTH(주문일) 주문월, COUNT(*) FROM 주문
WHERE DATEDIFF(발송일, 요청일) > 0
GROUP BY 1
ORDER BY 1;
문제2
제품 테이블에서 아이스크림 제품들에 대해 제품명별로 재고합을 보이시오
SELECT 제품명, SUM(재고) FROM 제품
WHERE 제품명 LIKE '%아이스크림%'
GROUP BY 1;
문제3
고객테이블에서 마일리지가 50000점 이상인 고객은 vip, 그렇지않으면 일반고객으로 구분하고, 고객구분별로 고객수와 평균 마일리지를 보이시오
SELECT IF(마일리지 >= 50000, 'vip', '일반고객') as 고객등급, COUNT(*), AVG(마일리지) FROM 고객
GROUP BY 고객등급;