지혜의 개발공부로그
지혜의 개발공부로그
머신러닝 - 비지도학습(DBSCAN)
27 Aug 2025 | Machine Learning개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
DBSCAN이란?
밀도 기반의 군집 알고리즘.
- 군집의 개수, 즉 K값을 미리 지정할 필요가 없음
- 유클리드 거리 기반의 k-means와 달리 오밀조밀 몰려있는 클러스터를 군집하는 방식을 사용
- 따라서 원 모양이 아닌 불특정한 형태의 군집도 존재함
- 클러스터가 최초의 임의의 점 하나로부터 점점 퍼져나가는데, 그 기준이 바로 일정 반경 안의 데이터의 밀도임
K-means와의 차이점
- K-Means:
클러스터의 중심(센트로이드)를 기준으로 데이터를 나눔- 각
데이터의 거리를 계산해(유클리드 거리 기반)그룹간 적정 수준의 거리에 따라 그룹을 구분 - 이때
클러스터의 수(K)를 미리 정해줘야 함 이상치에 굉장히 민감함! > 하나의 이상치가 중심을 크게 바꿀 가능성이 있음
- 각
- DBSCAN:
밀도 기반으로 클러스터를 생성함특정 반경 안에 min_samples 개수 이상의 점이 있다면, 밀집 구역으로 보고 클러스터로 간주함- 즉
클러스터 수(K)를 미리 정할 필요가 없음> 알아서 정해줌 - 군집에 속하지 못할 경우
noise(잡음)로 분류됨
- KMeans = “내가 몇 개 그룹이 필요해!” 하고 미리 정한 후에 거리에 따라 빠르게 분류
- DBSCAN = “데이터의 밀도에 따라서, 알아서 뭉쳐보자” + “이상치는 빼자”
그럼 각각 언제 사용하는 것이 좋을까?
- 2개의 모델을 다써보고 설명력이 더 좋은것을 선택
- 데이터의 상태를 봤을 때, 더 적합한 모델을 선택하는 식으로 선택
- K-means
- 데이터가 구형이나, 블록으로 나뉠 떄(거리니까 거리에 따라서 분류되는게 좋을떄)
- 클러스터 갯수를 알고 있을떄
- 속도와 단순한 것이 더 좋을떄 + (K-means가 DBSCAN보다 속도가 더 빠름)
“대규모 데이터 분류, 라벨이 없는 데이터, 군집의 수를 알 떄”
- DBSCAN
- 데이터에 이상치(Outlier)가 많을 떄
- 클러스터 개수를 모를떄
- 클러스터가 구형이 아닐떄 (한곳에 몰려있는 형태)
- 데이터가 저차원 (2,3D)에 가까울때
“이상치가 많은 데이터, 복잡한 모델을 분류할 때”
실습해보기 1
- 코어포인트 생성(eps반경 내 min_samples개 이상의 점이 존재하는 중심점)
- 코어포인트로부터 거리 측정(eps)
- 그 거리안 최소 갯수 설정(min_samples)
- border poins: 군집의 중심은 못되지만 군집에는 속하는 점
- noise point: 군집에 포함되지 못하는 점
# 라이브러리 불러오기
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import DBSCAN
# 데이터 불러오기
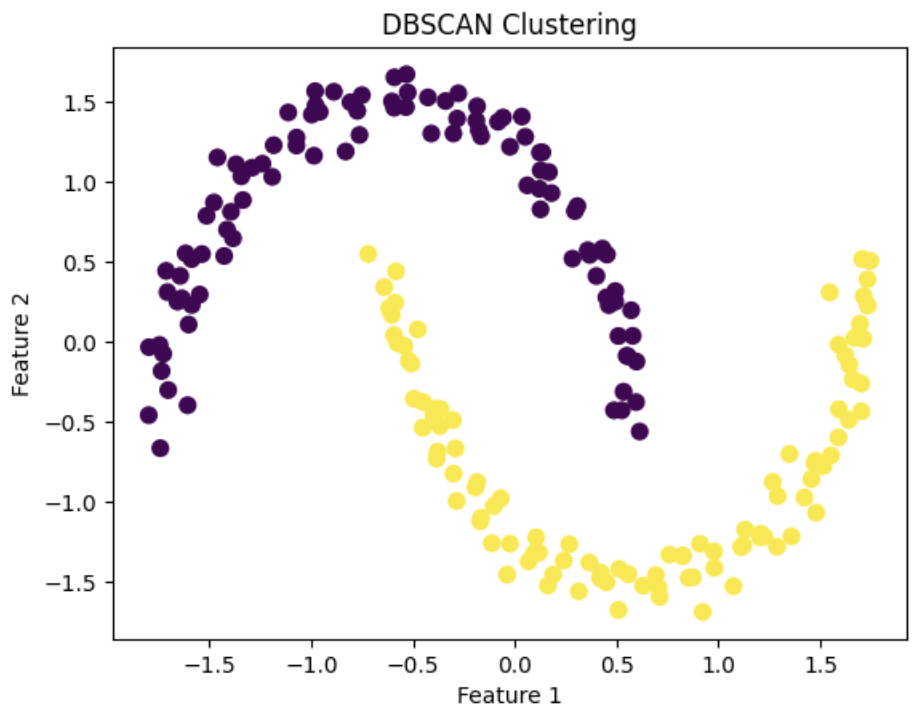
X, _= make_moons(n_samples=200, noise=0.05, random_state=0)
# 데이터 전처리(>정규화)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 모델 정의
dbscan = DBSCAN(eps=0.4, min_samples=2) # eps: 거리
dbscan_labels = dbscan.fit_predict(X_scaled)
# 시각화
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=dbscan_labels, cmap='viridis', s=50)
plt.title('DBSCAN Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()
실습해보기 2
# 라이브러리 불러오기
from sklearn.datasets import make_blobs
# 데이터 불러오기
X, _ = make_blobs(n_samples=300, cluster_std=0.6, random_state=42)
# 데이터 정규화
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 모델 정의
dbscan = DBSCAN(eps=0.1, min_samples=2)
# dbscan = DBSCAN(eps=2, min_samples=2)
dbscan_labels = dbscan.fit_predict(X_scaled)
# 시각화
plt.scatter(X_scaled[:, 0], X_scaled[:, 1], c=dbscan_labels, cmap='viridis', s=50)
plt.title('DBSCAN Clustering')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()