
 지혜의 개발공부로그
지혜의 개발공부로그
머신러닝 - 분류 모델의 평가지표(Classification)
26 Aug 2025 | Machine Learning개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
분류 모델의 평가지표(Classification)이 왜 중요한가?
모델 성능을 잘못 해석하면 실제로는 못 쓰는 모델을 선택할 수 있고, 비즈니스 목표(예: 불량 최소화/조기경보/추천 정확성)와 어긋난 판단을 내릴 수 있다.
핵심: “문제의 성격(분류/회귀/랭킹/불균형 등)과 비즈니스 목표”에 맞는 지표를 고르는 것이 성능 수치 그 자체보다 중요
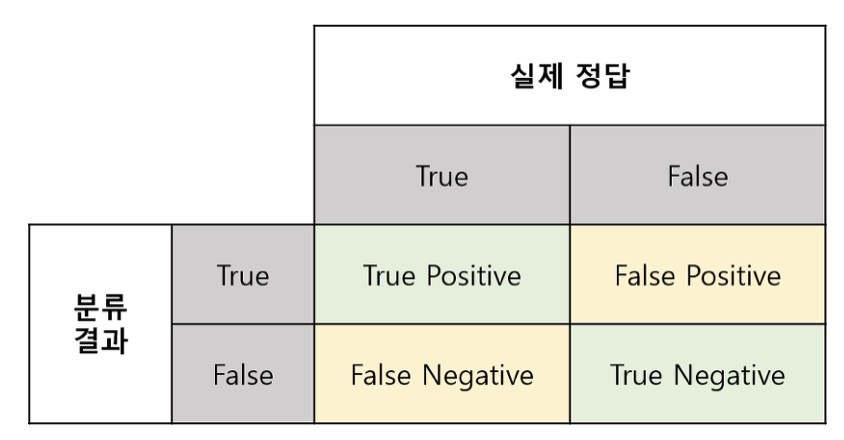
- TP(진양성): 실제 양성을 양성으로 맞춤
- TN(진음성): 실제 음성을 음성으로 맞춤
- FP(위양성, Type I 오류): 실제 음성인데 양성으로 잘못 예측
- FN(위음성, Type II 오류): 실제 양성인데 음성으로 잘못 예측
정확도(Accuracy)
실제와 맞게 예측한 확률
\[{Accuracy}=\frac{TP+TN}{TP+TN+FP+FN}\]정밀도(Precision)=예측력
예측을 참이라고 했는데, 실제로도 참인 확률
- 해석: “양성이라 예측한 것 중 실제로 맞춘 비율”
- 🕐 사용 시기: False Positive(오탐) 를 특히 줄여야 할 때
(예: 스팸 분류에서 정상메일을 스팸으로 막으면 곤란)
재현율(Recall, Sensitivity)=민감도
실제로 참인 경우, 예측도 참으로 한 확률
- 해석: “실제 양성 중에서 얼마나 잘 찾아냈는가”
- 🕐 사용 시기: False Negative(미탐) 를 특히 줄여야 할 때
(예: 질병 진단, 사기 탐지의 조기경보)
특이도(Specificity)
실제로 거짓인데, 예측도 거짓으로 한 확률
- 해석: “실제 음성을 얼마나 잘 골라내는가”
F1 점수(F1 Score)
정밀도–재현율의 조화평균
\[F1=2\cdot \frac{\text{Precision}\cdot \text{Recall}}{\text{Precision}+\text{Recall}}\]- 🕐 사용 시기: 두 지표 모두 중요하고, 불균형이 있는 경우
F-베타(F-β) 점수
\[Fβ=(1+\beta^2)\cdot \frac{\text{Precision}\cdot \text{Recall}}{\beta^2\cdot \text{Precision}+\text{Recall}}\]- β>1: 재현율에 더 큰 가중치
- β<1: 정밀도에 더 큰 가중치
- β=1: F1과 동일