
 지혜의 개발공부로그
지혜의 개발공부로그
머신러닝 - 로지스틱 회귀모델(Logistic Regression)
26 Aug 2025 | Machine Learning개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
로지스틱 회귀모델(Logistic Regression)란?
문제를 해결하기 위한 대표적인 지도학습 알고리즘 > 분류 알고리즘이다.
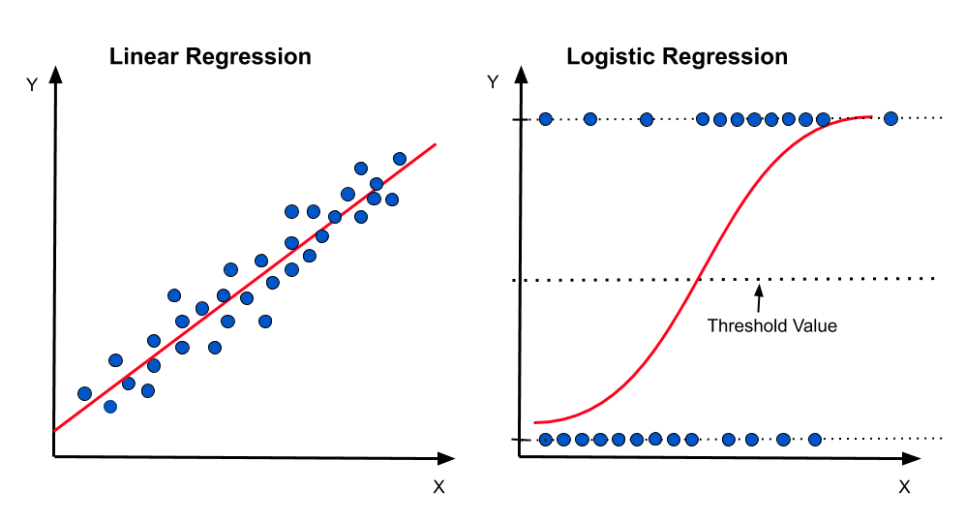
특징
- 이진 분류: 두 개의 클래스를 구분 (예: 스팸/정상 메일)
- 확률 예측: 0과 1 사이의 확률값으로 결과 출력
- 시그모이드 함수: S자 곡선 형태의 활성화 함수 사용
- 선형 결정 경계: 데이터를 선형적으로 분리
라이브러리 불러오기
import numpy as np # 넘파이
import pandas as pd #pandas
from sklearn.model_selection import train_test_split #데이터 분리
from sklearn.linear_model import LogisticRegression #LogisticRegression 로지스틱 회귀모델
from sklearn.preprocessing import StandardScaler #StandardScaler 데이터 정규화
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report #범주형에 따른 새로운 매트릭
import matplotlib.pyplot as plt #시각화
import seaborn as sns#시각화
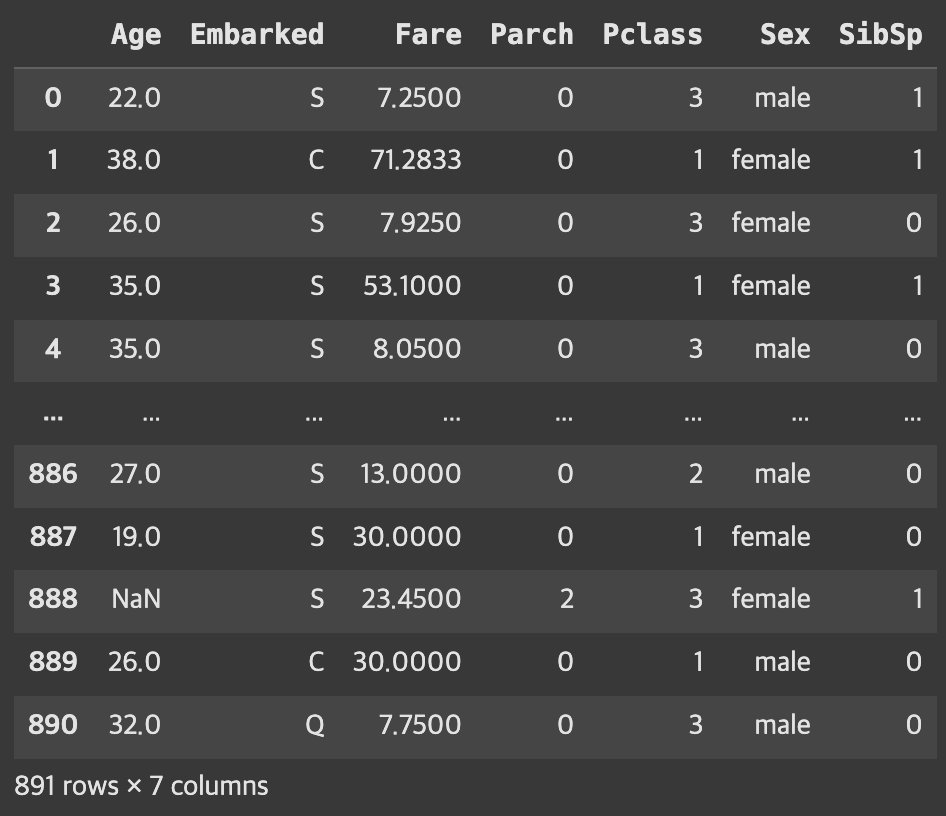
데이터 불러오기
train = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/titanic/train.csv')
test = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/titanic/test.csv')
target = 'Survived'
# difference > 필요없는 컬럼들 빼줌 / 따라서 feature안에는 필요한 애들만 들어가있는 것!
features = train.columns.difference(['Survived', 'PassengerId', 'Name', 'Ticket', 'Cabin'])
X = train[features]
y = train[target]
# 교안이 잘 만들어짐! > X!
# 스케일링은 X만 스케일하기 때문에 대부분 X랑 y로 분할 한다음에 X만 스케일링 함
X
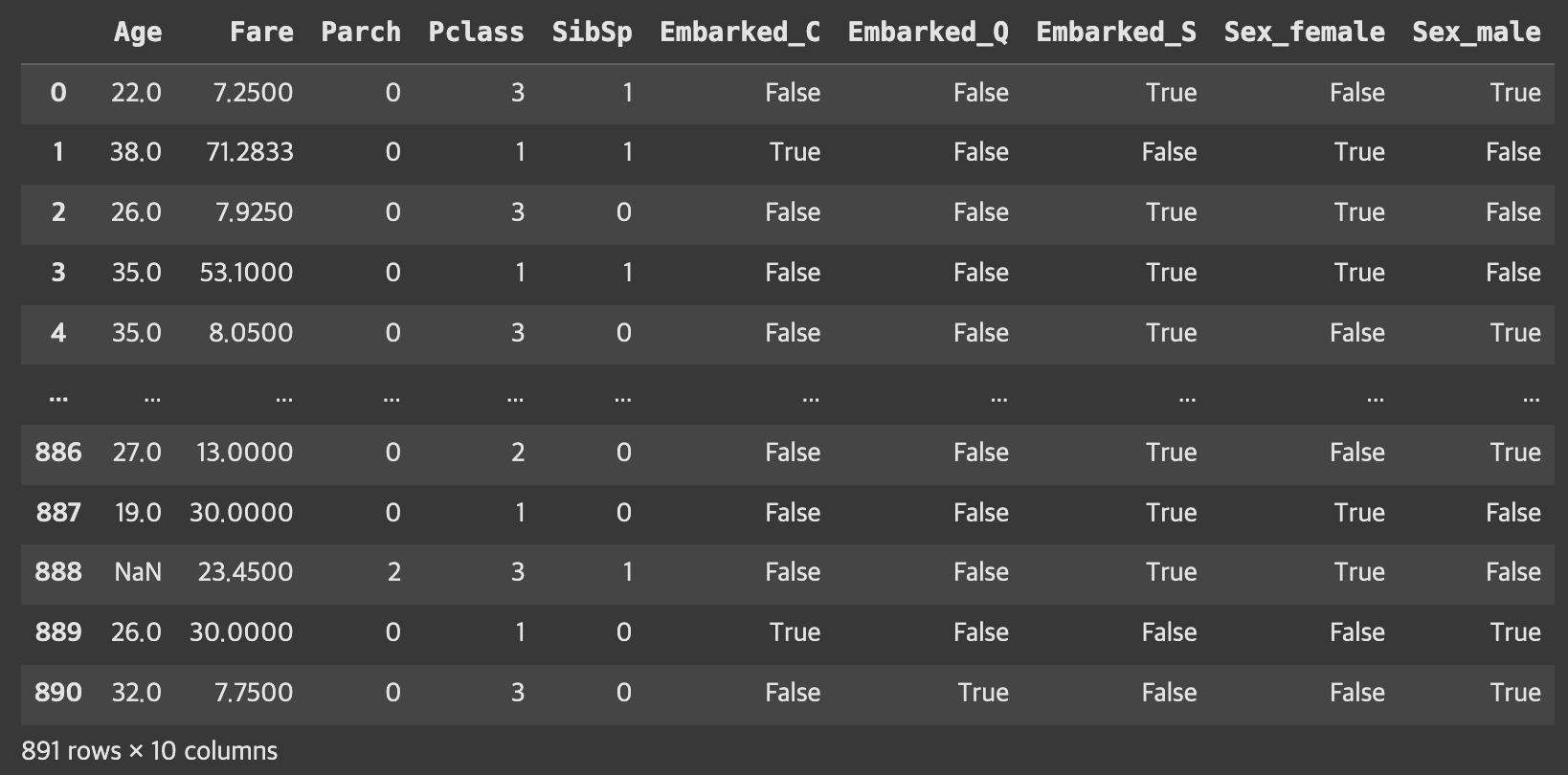
데이터 전처리 - 원 핫 인코딩
from sklearn.preprocessing import OneHotEncoder
# get dummies를 쓰거나 scikit-learn 를 쓰거나 둘 중 하나를 선택
X = pd.get_dummies(X) #, drop_first=True)
X
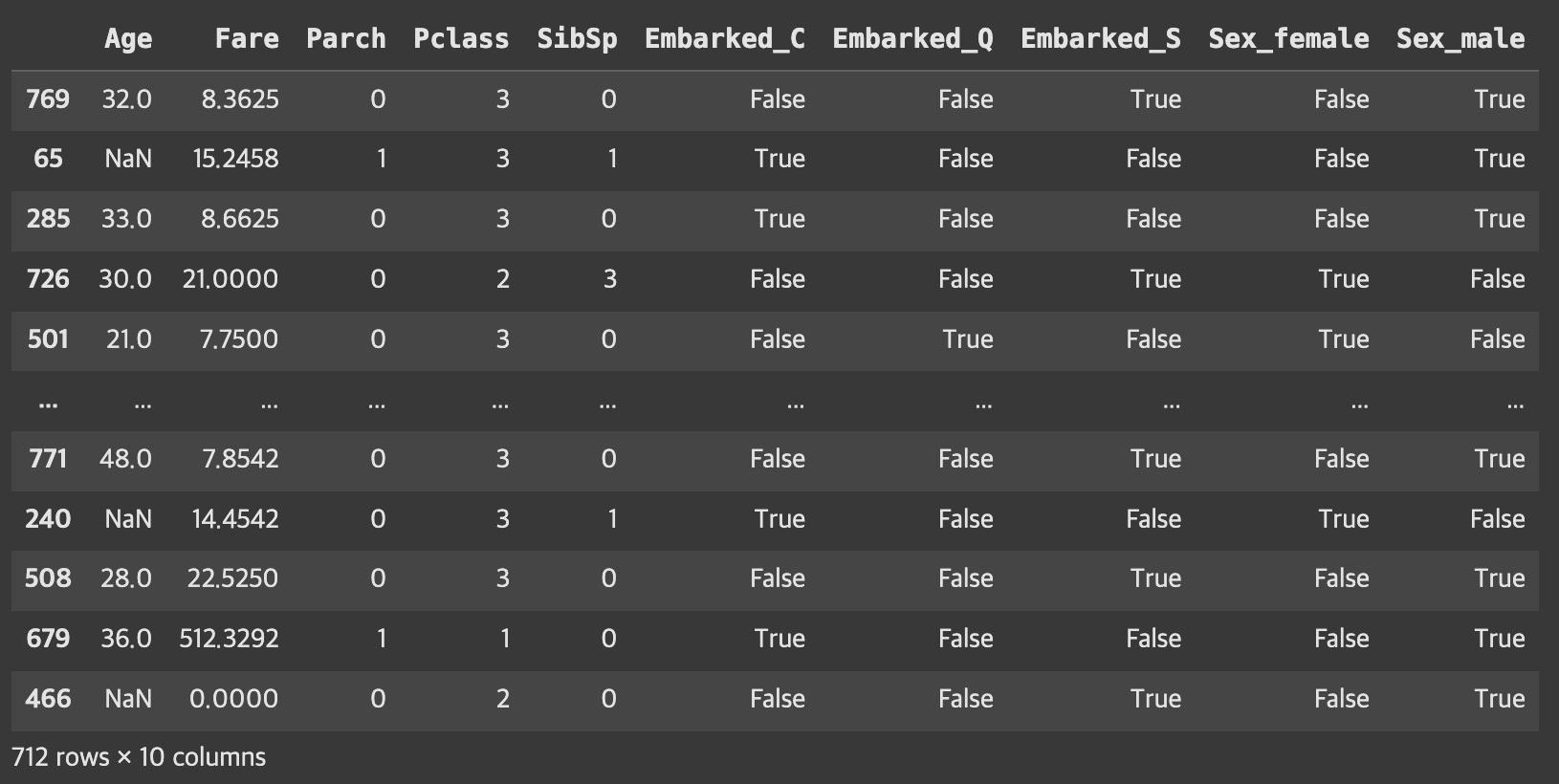
데이터 분할
# 위에서 만든 교안 X은 0,1로 바꿔진 상태인데 80% train, 20% test로 분리하겠다는 뜻 !
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2)
X_train
결측값 처리 > sklearn
from sklearn.impute import SimpleImputer
# 훈련된 train 데이터에 결측값이 있을 수 있음!
# > pandas에서 처리할지 sklearn에서 처리할지는 알아서 선택!
# strategy='mean': 결측값을 자동으로 찾아 평균값을 넣어주는 것 > 다 수치형이나까 평균값을 넣어도 됨
imputer = SimpleImputer(strategy='mean')
X_train_imputed = imputer.fit_transform(X_train)
X_val_imputed = imputer.transform(X_val)
특성 스케일링
from sklearn.preprocessing import StandardScaler
# 특성이란 것이 feature > 컬럼값이라는 뜻인데
# 표준편차에 집어넣어서 다 0+-a로 바꾸게 됨
# 이 특성 스케일링을 지나고 나서 남는 최종 결과물은 0.~ 1.~ 이런식으로 표준화된 값이 나옴
# 기존 데이터들이 다 바뀜 > 컴퓨터는 이게 판단하기가 더 쉬움!
# 즉, 각기 다른 수치들의 단위를 맞춰주는 것이 스케일링!
scaler = StandardScaler()
# 스케일링을 한 데이터로 학습 시켰으니까 모델은 스케일링한 데이터로 학습이 되었겠죠?
# 그렇다면 스케일링을 안한 데이터로 평가를 하면 정확도가 떨어지기 때문에
# 테스트와 훈련 모두 스케일링 처리를 한다~ 고 이해하시면 되요!
# 스케일링 했으면 train과 test 둘다 해줘야함
# 둘다 똑같이 작업한 다음에 비교해줘야함
X_train_scaled = scaler.fit_transform(X_train_imputed)
X_val_scaled = scaler.transform(X_val_imputed)
모델학습
from sklearn.linear_model import LogisticRegression
# f(X_train_scaled) = y_train
# f(X_train_scaled) = y^
model = LogisticRegression(random_state=42)
model.fit(X_train_scaled, y_train)
결과 예측
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
# y_val: 실제 정답 / y_pred: 예측 값 > 이 둘을 가지고 정확도를 측정해야함!
# y^ 과 y_val 비교
y_pred = model.predict(X_val_scaled)
모델 평가
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
accuracy = accuracy_score(y_val, y_pred) # 정확도
precision = precision_score(y_val, y_pred) # 정밀도
recall = recall_score(y_val, y_pred) # 재현율
f1 = f1_score(y_val, y_pred)
print(f"정확도 :{accuracy:.2f}")
print(f"정밀도 :{precision:.2f}")
print(f"정확도 :{recall:.2f}")
print(f"f1 score :{f1:.2f}")
# 정확도 :0.77
# 정밀도 :0.67
# 정확도 :0.74
# f1 score :0.71
지도학습과 비지도 학습
- 지도 학습: y(결과값)가 주어진 경우
- y가 수치형인 경우: 회귀모델
- y가 범주형인 경우: 분류모델(로지스틱 회귀모델..)
- 이 외에도 KNN, 나이브베이즈, SVM, 결정트리, 앙살블(그래디언트 부스트, 랜덤포레스트, 부스팅..), 스태킹..
- 비지도 학습: y(결과값)가 주어지지 않은 경우
- 군집 분석
- K-means, DBScan, 덴드로그램
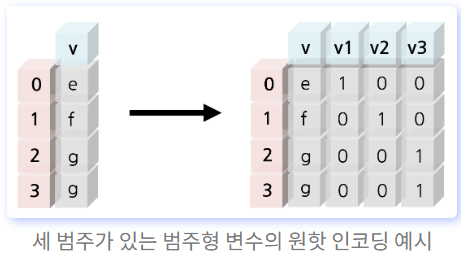
원핫 인코딩(One-Hot Encoding)
표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식을 말하며, 이렇게 표현된 벡터를 원-핫 벡터(One-Hot vector)라고 한다.
- 원핫인코딩 하기에 적합한 경우
- 데이터가 범주형이어야 함
- 범주형이더라도 숫자형이면 꼭 할 필요 없고, 문자형일 경우 하면 좋음!
ex) 타이타닉 데이터셋에서
- 적합한 경우 : sex, embarked
- 부적합한 경우 : pclass & name
- pclass는 범주형이기는 하지만 이미 숫자이기 때문
- 즉, 변경 여부가 모델학습에 큰 영향을 미치지 않음
pd.get_dummies(df, columns=['sex','embarked'], dtype='int')
# pandas 사용
pd.get_dummies(df, columns=['범주형_컬럼'])
# scikit-learn 사용
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
encoded = encoder.fit_transform(data)
레이블 인코딩
그 외 대표적인 인코딩 기법에는 레이블 인코딩이 있으며 이는 각 범주에 고유한 정수를 할당하여 숫자로 변환하는 방식을 말한다.
(예를들어, C : 0, Q : 1, S : 2) 이런식으로 각 값마나 숫자를 부여함!
info = {C : 0, Q : 1, S : 2}
df['embarked'].map(info)