
 지혜의 개발공부로그
지혜의 개발공부로그
머신러닝 - 교차검증(k-fold cross_validation)
26 Aug 2025 | Machine Learning개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
교차검증(k-fold cross_validation)란?
전체 데이터셋을 k개의 fold로 나누어 1개의 fold를 test data로, 나머지 (k-1)개의 foldfmf train data로 분할하는 과정을 반복함으로써 train, test data를 교차 변경하는 방법론
즉, 학습데이터 셋과 검증 데이터 셋을 점진적으로 변경하면서 마지막 k번째까지 학습, 검증을 수행함!
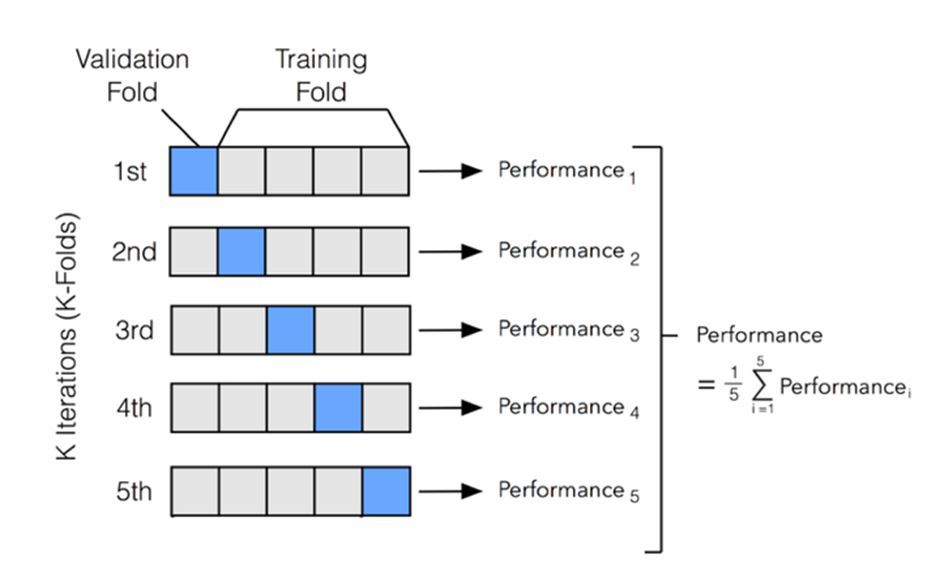
진행순서
- 데이터 분할(설정할 수 있는 하이퍼파라미터)
- 반복학습
- 성능측정: 각 반복에서 검증 성능 측정
- 각 점수를 평균, 표준편차 계산
이 작업을 왜 하는걸까?
- 과적합을 줄일 수 있음
- 측면 반복학습이다 보니 성능이 안정적일 수 있고,
- 기존 하나의 데이터를 뜯어볼수 있어 데이터 활용이 극대화 됨
구현해보기
# k-fold 라이브러리 불러오기
from sklearn.model_selection import KFold, cross_val_score
df = pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/house-prices/house_prices_train.csv')
X= df[['GrLivArea', 'LotArea']]
y = df['SalePrice']
# 선형회귀모델 정의
simple_model = LinearRegression()
# 모델 훈련
simple_model.fit(X,y)
# n_splits > 5개로 나누고, 섞어줌 (그래서 실행마다 array값이 조금씩 바뀜!)
kf = KFold(n_splits=5, shuffle=True, random_state=42)
# 훈련 끝난 데이터, 데이터, y값, scoring=평균으로 계산할지? 표준편차로 계산할지? ,cv=내가 정의한 kfold 정보를 넣으줌
# 사이킷런 규칙으로 MSE는 값을 음수로 반환
# 사이킷런은 모든 평가 점수를 클수록 좋은 점수로 규칙을 맞춰놓음 > 근데 MSE는 작을수록 좋으니 규칙에 맞지않음
MSE_score = cross_val_score(simple_model, X, y, scoring='neg_mean_squared_error', cv=kf)
MSE_score
# array([-3.38953122e+09, -2.77111324e+09, -4.35654599e+09, -2.90526053e+09, -2.47771029e+09])
# 그래서 임의로 다시 우리가 그 값에 -를 붙여 양수로 반환시킴 > 이게 진짜 우리가 보고싶은 MSE 값임!
-MSE_score.mean()
# np.float64(3180032254.0430913)