
 지혜의 개발공부로그
지혜의 개발공부로그
머신러닝 - Bias(편향)와 Variance(분산)?
26 Aug 2025 | Machine Learning개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
Bias, Variance
- Bias: 편향, 모델이 예측한 값과 실제 정답 간의 오차를 의미
- Variance: 분산, 모델이 예측한 값이 서로 얼마나 퍼져있나를 의미하는 수치
Bias
탁구공, 농구공 등의 데이터가 들어왔을 때, 이것을 공으로 분류해야하지만 동그라미로 분류하게 되면 실제 정답간의 차이가 생기게 된다. 이 차이의 정도를 bias라고 한다.
Variance
- 모델의 variance가 낮다 = 모델의 복잡도가 낮다
- 모델의 variance가 높다 = 모델의 복잡도가 높다
동그란 것을 공으로 분류한다고 생각해보자. 이때는 동그랗다는 특징만 가지고 있기 때문에 탁구공, 농구공의 문양과 같은 국소적인 특징에는 집착하지 않아도 된다. 따라서 탁구공, 농구공에 대해 모델이 비슷한 값을 출력할 것이다. 즉, variance가 낮게 나올 것이다.
즉, 우리가 ‘공’이라고 분류하고 싶은 데이터에 대해서 모델이 출력하는 값 또한 ‘공’으로 비슷할 것
그러나 동그랗고, 맨들거리고 등등과 같은 다양한 특징을 공을 분류하기 위해 사용한다면 탁구공, 농구공에 대해 모델의 값이 많이 달라질 것이다. 농구공은 겉이 꺼끌거리지만 탁구공은 부드럽기 때문에 같은 공임에도 불구하고 예측값이 다르게 나올 것 이다. 즉. variance가 높게 나올 것이다.
데이터를 ‘공’으로 분류하고 싶지만 추가적인 특징들이 모델을 다른 공으로 분류하도록 할 수 있음
따라서 같은 공을 분류함에도 어떤 특징을 사용하느냐에 따라 예측값의 퍼져있는 정도, 데이터셋의 예민한 정도가 다 다르다. 이러한 것을 측정하는 데에 사용하는 것이 variance이다.
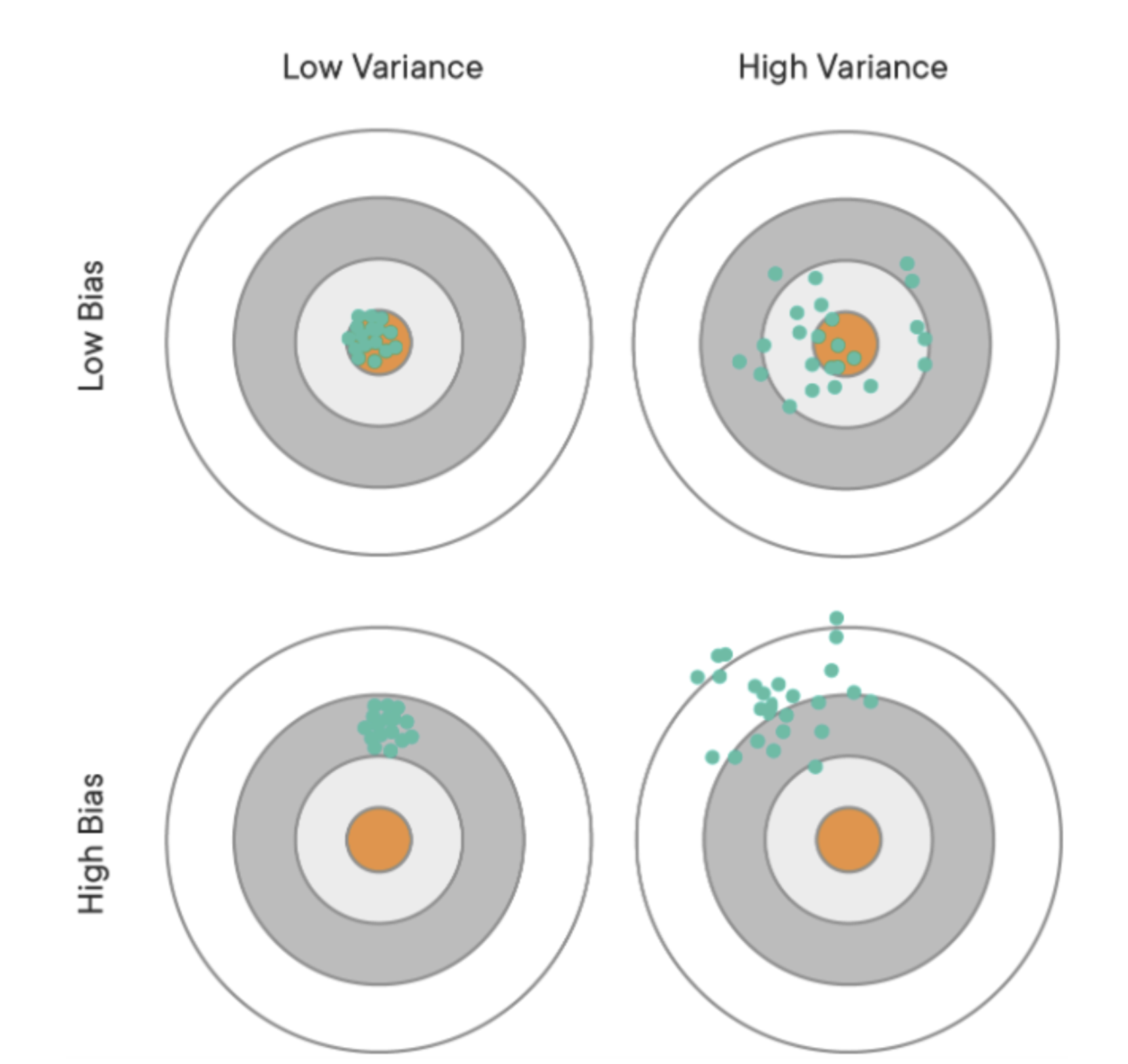
위 그림은 train, test 데이터에 대한 결과를 bias, variance 관점에서 해석한 그림이다. 이는 MSE 수식을 통해 바라볼 수 있다.
- 가운데 주황색 동그라미 영역은 target으로, 정답&참값을 의미함
- 초록색 점들은 모델이 예측한 값을 의미함
- Low Bias & Low Variance (좌상단): 실제 정답과 예측 값들의 차이가 적고, 예측값들의 variance도 낮아서 loss가 낮은 모델이다. 모든 데이터셋에서 이러한 경향을 보인다면 학습이 잘 되었다고 볼 수 있다.
- Low Bias & High Variance (우상단): 예측한 값을 평균한 값은 정답과 비슷한데, 예측값들의 variance가 높아 loss가 높은 모델아다.
- High Bias & Low Variance (좌하단): 예측값들의 variance는 낮지만 실제 정답과의 차이가 큰 경우로 학습이 잘 안 된 경우로 볼 수 있다.
- High Bias & High Variance (우하단): Bias와 Variance 둘 다 높아 학습이 잘 안 된 경우이다.