
 지혜의 개발공부로그
지혜의 개발공부로그
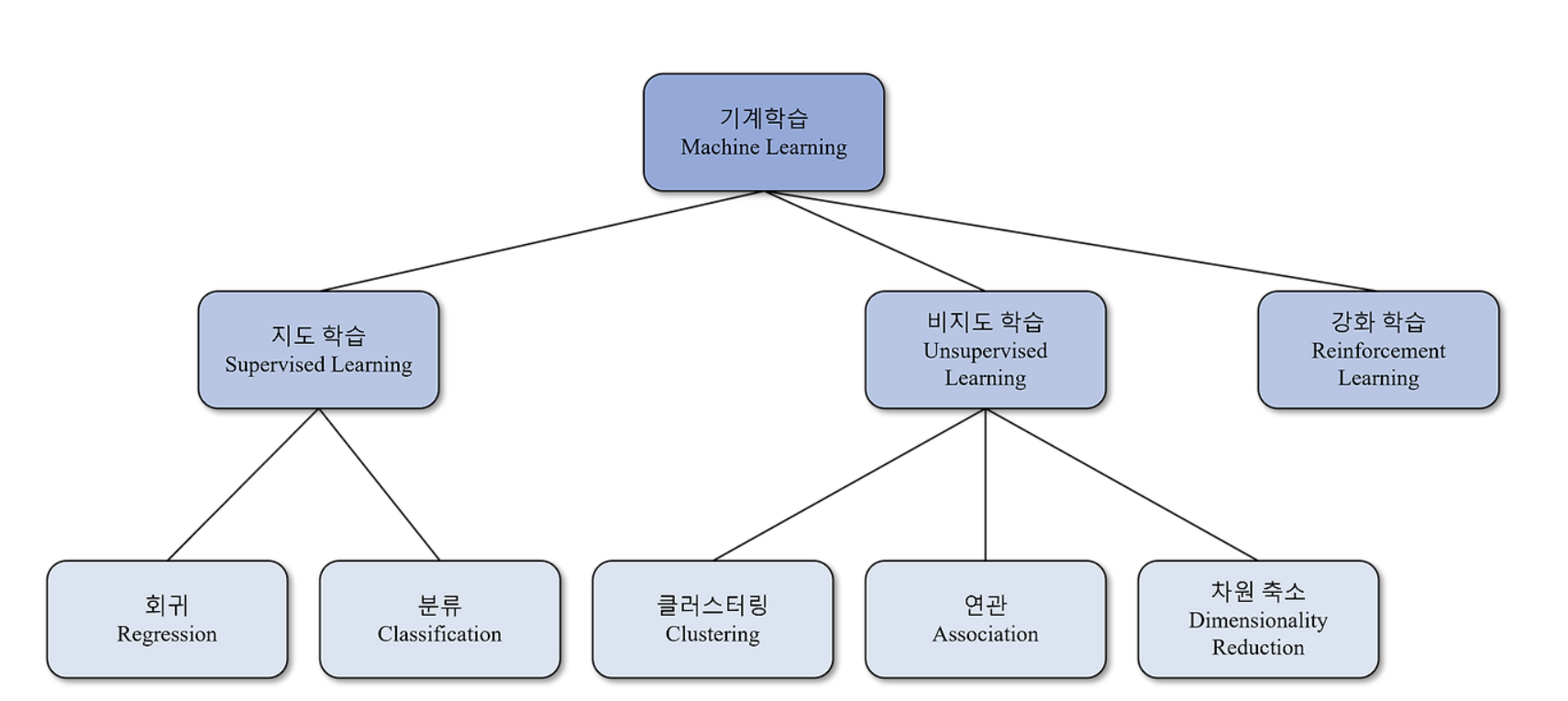
머신러닝 - 지도 & 비지도 학습 의미와 종류
25 Aug 2025 | Machine Learning개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
지도학습(Supervised Learning)
지도학습 알고리즘은 정답이 있는 데이터(label)들을 학습한다. 그리고 이런 정답들은 사람들이 직접 데이터 하나하나에 표기(annotate)한다.
대표적인 기술로 분류(classification), 회귀(regression)이 있다.
예를 들어, 사진 분류의 문제 중 하나인 ‘개, 고양이 사진분류’를 지도학습을 통해 해결하고자 한다고 상상해보자.
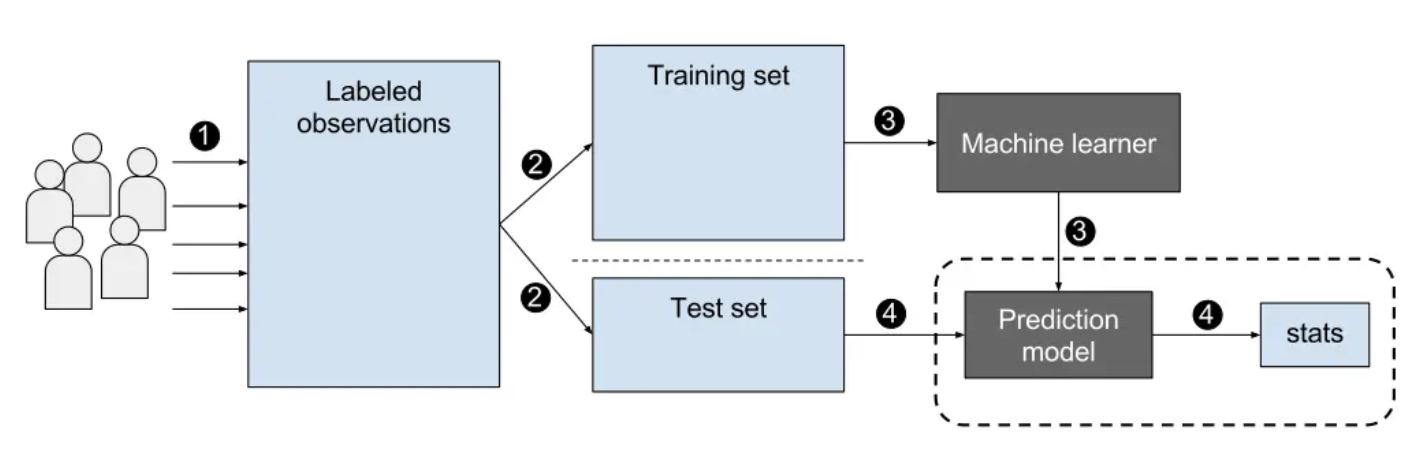
- 지도학습 속 train을 위해 굉장히 많은 개, 고양이 사진들이 필요함
- 각 사진들이 개인지 고양인지 라벨(label)을 해줘야 함
- 이렇게 label 된 데이터 묶음을 training set, test set으로 나눔
- 기계는 training set을 통해 사진을 통과시켜 개인지 고양이인지를 예측
- 지도학습
훈련을 통해 예측값(predict)와 만들어둔 정답(label)이 같아지도록 함
즉, 기계의 예측(prediction)이 우리가 의도하는 정답(label)과 같아지도록 지도(supervised) 하는 것!
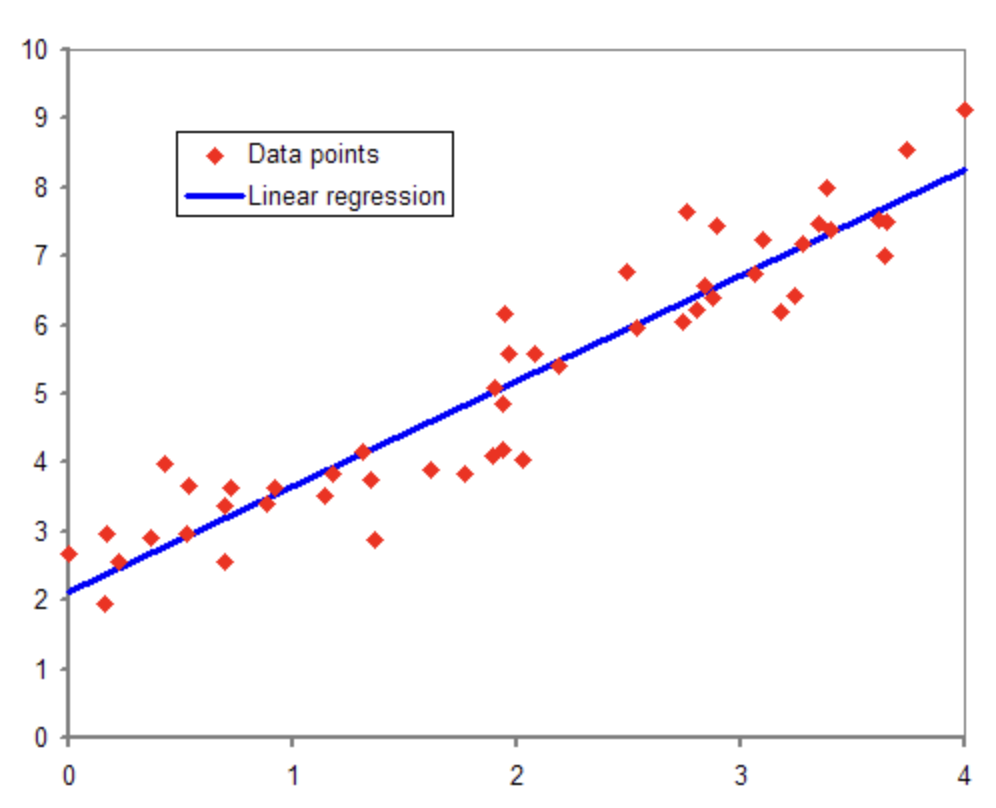
위 지도학습은 분류모델을 사용한 것이었다면 또다른 지도학습으로는 회귀모델이 있다.
이 회귀 알고리즘은 주어진 데이터(X)를 기반으로 정답(Y)를 잘 맞추는 fit함수를 찾는 문제이다.
회귀 알고리즘은 예측값과 정답(Y)사이의 차이(거리)를 작게해 알고리즘을 학습하도록 한다.
- 분류 종류: 선형분류기(linear classifier), 의사결정트리(decision tree), 랜덤포레스트(random forest), svm(suppor vector machine), KNN(k-nearest neighbor), 나이브베이즈(Naive Bayes)
- 회귀 종류: 선형회귀(linear regression), 로지스틱회귀(logistic regression), 다항식회귀(polynomial regression)
비지도학습(Unsupervised Learning)
비지도학습 알고리즘은 정답(label) 없이 데이터를 학습한다. 목적은 인간의 개입이 없는 데이터를 스스로 학습하여 그 속의 패턴(pattern) 또는 각 데이터 간 유사도(similarity)를 학습하는 것이다.
대표적인 기술로 군집화(clustering), 연관(association), 차원축소(dimensionality reduction)이 있다.
- clustering: 정해진 분류 없이 기계가 스스로 데이터들을 보고 학습하여 비슷한 특징의 데이터를 군집화시키는 기술
- K-means..
- association: 데이터 간 관계 혹은 패턴을 학습
- 장바구니분석 및 추천 엔진
- dimensionality reduction: 차원이 높은 데이터의 학습을 조금 더 효율적으로 하기 위해 사용되는 기술로 고차원의 데이터를 저차원의 데이터로 만드는 것이 목적임
- 시각적 데이터에서 노이즈를 제거해 화질을 개선하는 경우와 같이 전처리 단계에서 사용
지도학습과 비지도 학습의 가장 큰 차이점
데이터 셋에 label이 지정되어 있는지 아닌지이다. 즉, 지도학습은 label이 있고 비지도 학습은 label이 없다.
- 지도학습 > 목표:
새로운 데이터의 결과를 예측하는 것- label된 데이터 셋을 이용해 반복적으로 데이터를 예측하고
정답(label)과의 오차를 줄여나가며 학습함 - 비지도 학습모델보다 더 정확한 경향이 있지만 데이터에 적절하게 레이블을 지정하려면 사람의 개입이 필요함
- 활용 목표: 스팸탐지, 감정분석, 일기예보 및 가격 예측에 이상적
- 단점: 훈련하는 데 시간이 많이 걸릴 수 있으며, 입력 및 출력 변수에 대한 label에는 전문지식이 필요함
- label된 데이터 셋을 이용해 반복적으로 데이터를 예측하고
- 비지도학습 > 목표: 많은 양의
새로운 데이터에 대한 통찰력을 얻는 것- label이 지정되지 않은 데이터의 고유한 구조를 발견하기 위해 자체적으로 작동
- 출력변수의 유효성을 검사하려면 여전히 사람의 개입은 필요함
- 활용 목표: 이상감지, 추천엔진, 의료영상에 적합
- 단점: 출력변수를 검증하기 위해 사람이 개입하지 않았을 경우, 부정확한 결과를 가질 수 있음
지도학습은 일반적으로 R or Python같은 프로그램을 사용해 계산되는 간단한 머신러닝 방법이다. 그러나 비지도학습에서는 대량의 분류되지 않은 데이터로 작업하기 위한 강력한 도구가 필요하다. 비지도 학습 모델은 의도한 결과를 생성하기 위해 대규모 훈련 셋이 필요하기 때문에 계산적으로 복잡하다.
지도학습, 비지도학습 중 뭐가 더 좋다고는 할 수 없고, 데이터 구조나 사용 분야에 맞게 적합한 방식을 선택하는 것이 중요하다!