
 지혜의 개발공부로그
지혜의 개발공부로그
Pandas 데이터 전처리해보기(예시)
30 Jul 2025 | DA개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
데이터 전처리
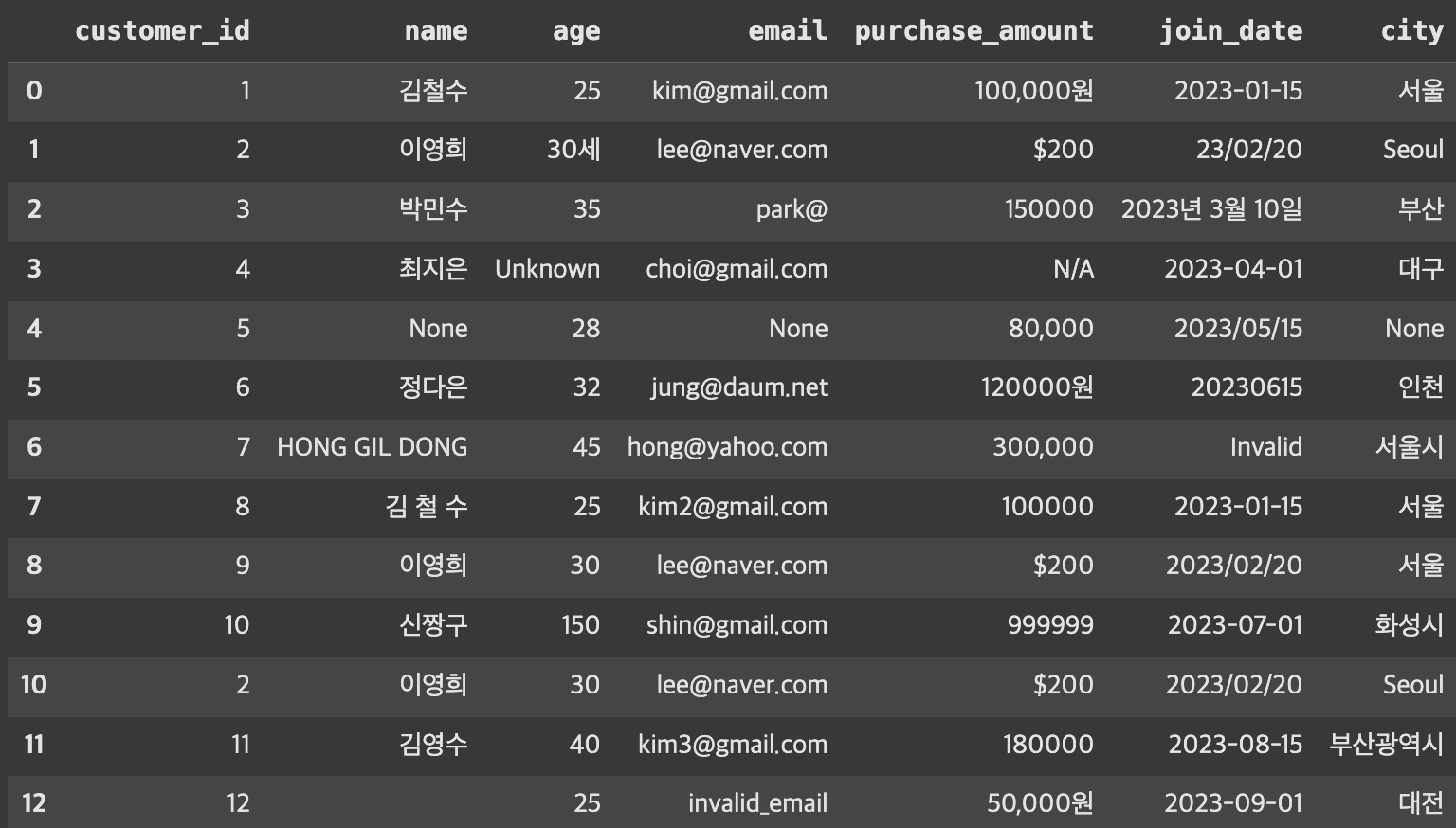
# 실제 지저분한 데이터
raw_data = {
'customer_id': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 2, 11, 12], # 중복 있음
'name': ['김철수', '이영희', '박민수', '최지은', None, '정다은', 'HONG GIL DONG', '김 철 수', '이영희', '신짱구', '이영희', '김영수', ''],
'age': ['25', '30세', '35', 'Unknown', '28', '32', '45', '25', '30', '150', '30', '40', '25'], # 다양한 형태
'email': ['kim@gmail.com', 'lee@naver.com', 'park@', 'choi@gmail.com', None, 'jung@daum.net', 'hong@yahoo.com', 'kim2@gmail.com', 'lee@naver.com', 'shin@gmail.com', 'lee@naver.com', 'kim3@gmail.com', 'invalid_email'],
'purchase_amount': ['100,000원', '$200', '150000', 'N/A', '80,000', '120000원', '300,000', '100000', '$200', '999999', '$200', '180000', '50,000원'],
'join_date': ['2023-01-15', '23/02/20', '2023년 3월 10일', '2023-04-01', '2023/05/15', '20230615', 'Invalid', '2023-01-15', '2023/02/20', '2023-07-01', '2023/02/20', '2023-08-15', '2023-09-01'],
'city': ['서울', 'Seoul', '부산', '대구', None, '인천', '서울시', '서울', '서울', '화성시', 'Seoul', '부산광역시', '대전']
}
df = pd.DataFrame(raw_data)
df
customer_id를 기준으로 중복 데이터 제거해보기
df.drop_duplicates(subset=['customer_id'], inplace=True)
나이 관련 전반적인 전처리
# 나이가 0-100사이면 그 숫자를 넣고, 아니면 np.nan
df['age'] = df['age'].where(df['age'].between(0,100), np.nan)
# 문자 '세' 없애기
df['age'].replace('세', '', regex=True, inplace=True)
# 알수없는 데이터에 np.nan
df['age'].replace(['Unknown','150'], np.nan, inplace=True)
# 문자형인 나이 모두 숫자로 변환 / errors='coerce' > 에러나는 애들은 그대로
df['age'] = pd.to_numeric(df['age'], errors='coerce').astype('Int64')
이메일 관련 전반적인 전처리
정규표현식을 사용해 전처리 해보자
reg = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+.[a-zA-Z]{2,}$'
df['email'] = df['email'].where(df['email'].str.match(reg, na=False))
구매금액 관련 전반적인 전처리
# 위에서 중복관련된 데이터 삭제함으로써 어지러워진 인덱스 재 정렬
df.reset_index(drop=True, inplace=True)
# 양옆의 공백 제거
df['purchase_amount'].str.strip()
for i in range(len(df)): # df의 컬럼 개수만큼 돌면서 (0~11)
# purchase_amount 문자형 데이터만 amount 에 대입된다
amount = str(df.loc[i,'purchase_amount'])
# amount가 str 타입인데, 한글자씩 순회중에 $가 있는게 있다면
if '$' in amount:
# $ 제거
clean = amount.replace('$', '')
# 환율 계산하면서 purchase_amount에 데이터를 대입
df.loc[i, 'purchase_amount'] = int(clean)*1391
else:
# 남은 데이터들의 전처리
clean = amount.replace(',','').replace('원', '')
# 이상치 혹은 NaN 친구들 처리
if clean in ['NaN', 'N/A', 'nan', '999999', '<NA>']:
# 원래 NaN 이런애들은 실제 None 타입으로 있어야함(str이면 안됨)
df.loc[i, 'purchase_amount'] = np.nan
else:
# 모두 int형으로 변환
df.loc[i, 'purchase_amount'] = int(clean)
이름 관련 전반적인 전처리
위 코드처럼 이름관련 데이터 전처리를 해봤다.
for i in range(len(df)):
amount = df.loc[i, 'city']
if amount in ['NaN', 'N/A', 'nan', '999999', '<NA>', None]:
df.loc[i, 'city'] = np.nan
else:
df['city'] = df['city'].replace(df.loc[i, 'city'], df.loc[i, 'city'][:2])
if amount == 'Se':
df['city'] = df['city'].replace('Se', '서울')
날짜 관련 전반적인 전처리
dateutil.parser 라이브러리를 사용했다. (설치는 할필요 없다)
일반적인 시간/날짜 포멧으로 파싱이 가능한 시간/날짜 스트링 파서를 제공
def safe_parse_date(x):
try:
# 컬럼에 널값이 있으면
if pd.isna(x):
# 그대로 널값을 두고
return pd.NaT
# 없는경우, 들어온 스트링값을 형식에 맞게끔 변환
return parse(str(x), fuzzy=True)
except Exception:
return np.nan # 변환 불가능한 값은 NaT로 처리
df['join_date'] = df['join_date'].apply(safe_parse_date)