
 지혜의 개발공부로그
지혜의 개발공부로그
Pandas 데이터프레임 합치기(concat, merge)
15 Jul 2025 | DA개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
데이터프레임 합치기
다수의 데이터프레임(DataFrame) 혹은 시리즈(Series)를 결합하는 방법에 대해 정리해본다.
pd.concat() > 데이터프레임 붙이기
데이터프레임을 말그대로 물리적으로 이어붙여주는 함수 > pd.concat(데이터프레임 리스트)로 사용
import pandas as pd
# df1, df2 데이터 프레임을 각각 만들어 주면서 각각의 index를 지정해줌
df1 = pd.DataFrame({'a':['a0','a1'],
'b':['b0','b1'],
'c':['c0','c1']},
index = [0,1])
df2 = pd.DataFrame({'a':['a1','a2','a3'],
'b':['b1','b2','b3'],
'c':['c1','c2','c3'],
'd':['d1','d2','d3']},
index = [1,2,3])
df1, df2는 각각 이렇게 출력될 것이다.
[Output]
a b c
0 a0 b0 c0
1 a1 b1 c1
a b c d
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3
이제 이 두 데이터프레임을 concat을 통해 합쳐보자.
result = pd.concat([df1, df2])
result
[Output]
a b c d
0 a0 b0 c0 NaN
1 a1 b1 c1 NaN
1 a1 b1 c1 d1
2 a2 b2 c2 d2
3 a3 b3 c3 d3
pd.concat()의 axis는 디폴트 0로 지정되어있기 때문에 둘의 합쳐진 방향이 아래로 이어붙여짐을 알 수 있다.(axis=0은 열기준, 위아래) 그리고 df1의 c는열은 존재하지 않기 때문에 c에 해당하는 데이터가 NaN으로 채워진것 또한 볼 수 있다. 그리고 더 나아가 데이터프레임을 붙일때 그냥 이어붙이다보니 인덱스 번호도 그대로 붙여진 것을 볼 수 있다. 이때는 ignore_index=True를 하면 인덱스 재배열이 가능하다.
- pd.concat(axis=0) 이 defalut
- 비워진 값은 NaN으로 채워짐
- 인덱스 재배열은 ignore_index=True
pd.concat(axis=1)을 하는 경우
axis=1은 행기준, 좌우방향!
result = pd.concat([df1, df2], axis=1)
result
[Output]
a b c a b c d
0 a0 b0 c0 NaN NaN NaN NaN
1 a1 b1 b1 a1 b1 c1 d1
2 NaN NaN a2 a2 b2 c2 d2
3 NaN NaN a3 a3 b3 c3 d3
이때 보면 느꼈겠지만 pd.concat()함수는 default로 outer를 가진다.
- outer: 합집합
- inner: 교집합
이때 그러면 inner옵션을 줘보도록 하자.
pd.concat(join=’inner’)을 하는 경우
result = pd.concat([df1, df2], axis=1, join='inner')
result
[Output]
a b c a b c d
1 a1 b2 c3 a1 b1 c1 d1
pd.merge() > 데이터프레임 병합
두 데이터프레임을 각 데이터에 존재하는 고유값(key)을 기준으로 병합할 때 사용(공통된 열 혹은 인덱스를 기준으로 두 테이블을 합침)
디폴트는 pd.merge(df_left, df_right, how=’inner’, on=None)이다. 예시로 위에 만들었던 데이터프레임을 다시 사용할 것이다. (이떄 on은 기준이 되는 열을 지정해주는 매개변수를 의미)
- left, right: 병합하려는 두 데이터프레임
- on: 기준이 되는 열 이름
- how(->join): 병합 방식, 기본은 inner(교집합) outer(합집합) left(왼쪽값 기준) right(오른쪽값 기준)
- suffixes: 중복된 열 이름에 접미사 추가 (기본값: ‘_x’, ‘_y’)
좀 더 보기 편한 데이터를 가져와 예시를 들어본다.
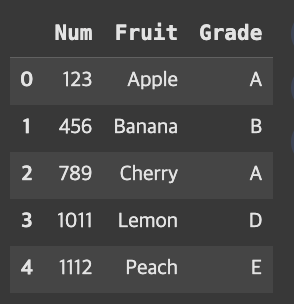
fruit = pd.DataFrame({'Num':[123, 456, 789, 1011, 1112],
'Fruit':['Apple', 'Banana', 'Cherry', 'Lemon', 'Peach'],
'Grade':['A', 'B', 'A', 'D', 'E']})
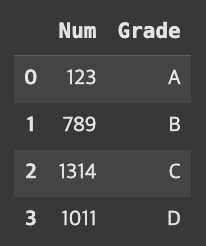
grade = pd.DataFrame({'Num':[123, 789, 1314, 1011],
'Grade':['A', 'B', 'C', 'D']})
pd.merge() 그냥 해보는 경우
아무 옵션을 적용하지 않으면, on=None이기에 두 데이터의 공통된 열인 Num과 Grade를 기준으로 교집합인 데이터가 반환된다.
result = pd.merge(fruit, grade)
result
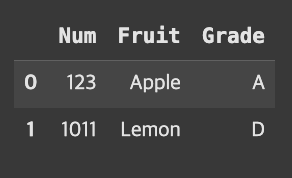
여기서 pd.merge(fruit, grade)는 pd.merge(fruit, grade, on=[‘Num’,’Grade’])와 동일하다.
pd.merge(fruit, grade, how=’outer’)의 경우
merge()의 how는 inner(교집합)가 디폴트이기때문에 outer(합집합)인 경우를 보겠다.
result = pd.merge(fruit, grade, how='outer')
result
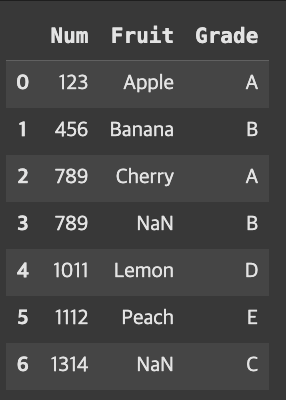
Grade에 존재하지 않았던 Fruit 값은 NaN으로 들어가있음을 볼 수 있고, 공통적으로 있던 값은 하나로 합쳐져 출력된 것을 볼 수 있다.
pd.merge(fruit, grade, how=’left or right’)
- how=’left’
result = pd.merge(fruit, grade, how='left')
result
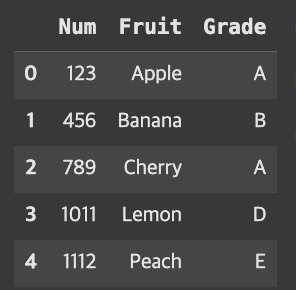
fruit에 관한것만 나오는것을 볼 수 있다. 그 이유는 pd.merge(fruit, grade, how=’left’)에서 데이터프레임의 순서가 fruit, grade 순서로 병합해준 것이기 때문이다. 따라서 왼쪽에 위치만 fruit에 관련된 데이터만 출력된 것을 볼 수 있다.
- how=’right’
result = pd.merge(fruit, grade, how='right')
result
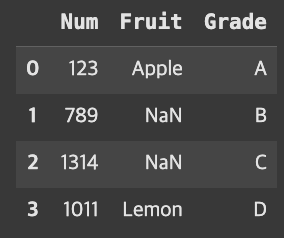
여기서도 마찬가지로 grade에 관련된 데이터만 나왔고, 비어있는 값에 대해서는 NaN으로 출력되어있다.
열을 지정해주는 경우
result = pd.merge(fruit, grade, on='Num')
result
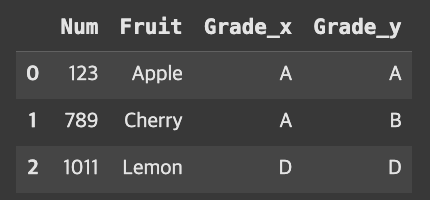
공통된 열 중에 Num 하나만 지정해주는 경우 재밌는 결과가 나온다.
Num을 기준으로 Fruit 데이터가 나오고 그에 대한 fruit, grade의 Grade 데이터가 나왔다.
열을 지정해주고 합집합으로 지정한 경우
result = pd.merge(fruit, grade, on='Num', how='outer')
result
공통된 열이 아닌 열을 기준으로 지정할때
result = pd.merge(fruit, grade, on='Fruit')
result
당연히 에러가 뜬다
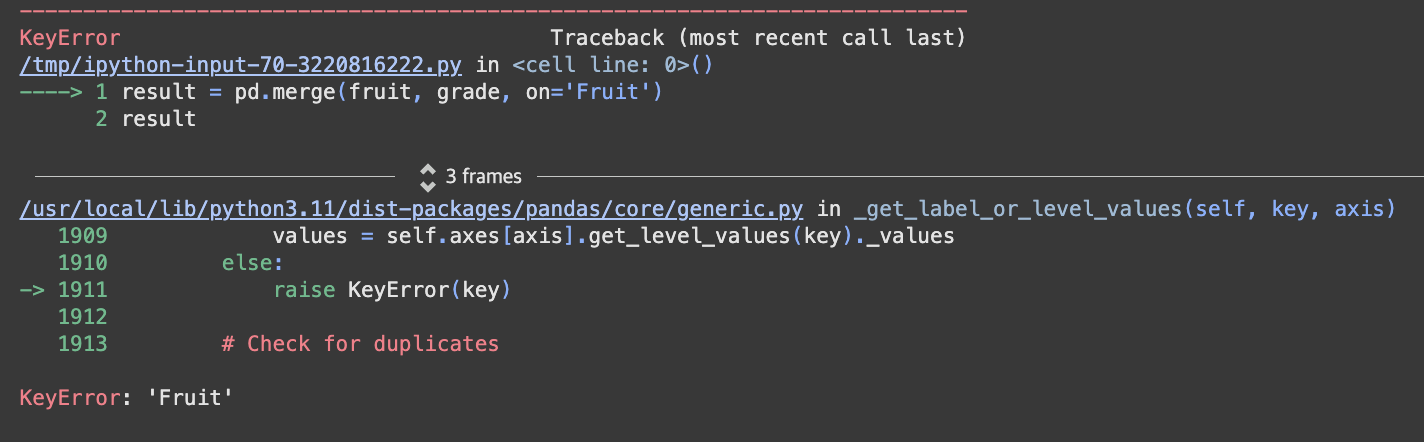
데이터프레임을 병합하는데에 있어서 흥미로웠던 점은 inner join을 했음에도, 공통되지 않은 열이 같이 결합되어 나왔다는 점이었다.
import pandas as pd
df1 = pd.DataFrame({'a':['a0','a1'],
'b':['b0','b1'],
'c':['c0','c1']},
index = [0,1])
df2 = pd.DataFrame({'a':['a1','a2','a3'],
'b':['b1','b2','b3'],
'c':['c1','c2','c3'],
'd':['d1','d2','d3']},
index = [1,2,3])
이렇게 데이터프레임 df1, df2를 각각 만들고 이 둘을 merge해본다고 하자.
result = pd.merge(df1,df2)
result
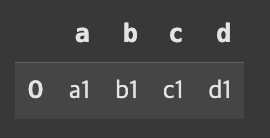
기본 how=inner'이기 떄문에 나는 당연하게 공통된 열 a,b,c에 대한 데이터만 나올 것이라고 생각했다. 혹여 d열이 나오더라도 안의 값은 NaN이 나오지 않을까? 했었다. 근데 이 merge를 함에 있어서 일정한 규칙이 있다고 한다.
즉, 이론상으로는 교집합만 합쳐지는 것이 맞지만 파이썬에서는 조금 다르게 설계 되어있다고 한다.
- 컬럼(열)정렬을 우선 > 각 데이터프레임이 가지고 있는 모든 열이 합해진다. 이때 공통된 컬럼이 기준으로 정렬되는 것. 중요한 것은 일단 모든 열이 다 합해진다는 것(d열이 나오는 이유)
- 로우(행) 정렬 > 값이 있으면(값이 올수있다면) 일단 다 가져온다. 이때 없는 경우 NaN이 채워진다.(d1이 나오는 이유)
다시 교집합을 하는 방법을 정리해보면,
- 데이터프레임이 가진 모든 열이 합쳐지고
- 교집합에 부합하는 행과 열이 있다면
- 교집합에 해당하지 않은 행 값은 탈락되지 않고
- 공통되는 행과 열에 남아 들어온다
이러한 이유는 SQL과 Pandas의 디자인 철학 때문이라고 한다.
- 기본적으로 join조건은 행을 매칭하는 기준으로 사용
- 데이터분석을 하는 경우, 더 많은 경우에 관련된 전체 정보가 필요함
따라서, SQL과 Pandas는 데이터분석을 위한 도구로서 데이터분석을 하기에 가장 좋은 방식으로 디자인되어 이렇게 설계된것이라고 이해하면 쉬울 것 같다!
궁금증 완료 !