
 지혜의 개발공부로그
지혜의 개발공부로그
Pandas 사용해보기
11 Jul 2025 | DA개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
Pandas 사용해보기
사용에 앞서 일단 import 해주기!
import pandas as pd
우선 딕셔너리를 통해 데이터프레임 하나를 생성해보도록 하자.
# 데이터프레임에 전달할 딕셔너리 생성
characters = {
'캐릭터명': ['조조', '유비', '관우', '지혜', '판다'],
'체력': [120, 80, 100, 90, 110],
'공격력': [85, 95, 80, 75, 60],
'방어력': [90, 40, 60, 55, 85],
'마나': [30, 150, 50, 40, 120]
}
# 일반적
df_character = pd.DataFrame(character)
# 인덱스를 지정해주는 경우 > column을 추가하는데, 어떤것을 인덱스로 설정할지 지정
df_character = pd.DataFrame(character, index = [*])
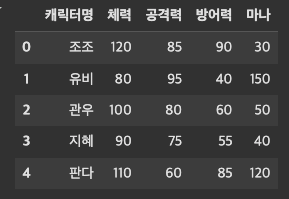
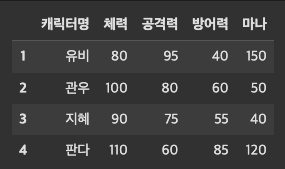
이렇게 만들어준 딕셔너리(character)를 데이터프레임으로 만들면 아래와 같이 생성이 된다.
DataFrame에서의 copy()힘수는 얕은 복사임에도 깊은 복사 효과를 볼 수 있다고 한다. 즉 copy()함수를 사용하더라도 원본에 영향을 주지는 않는다는 것.이는 pandas만의 특징이라고 하는데, 이를 통해 메모리를 적게 차지하여 메모리 효율성을 높일 수 있다. (깊은 복사하는 방법: .copy(deep=True))
이렇게 만든 데이터프레임으로 무얼 할수 있는지 봐보자
인덱싱과 슬라이싱
수천 수만개의 데이터를 다루다보면 원하는 데이터만 쏙쏙 뽑아 보고싶어질 것이다. 이때 사용하는 것이 인덱싱, 슬라이싱이다.
# 1. column(열)을 직정 지정해 뽑아내는 방법
cols =['체력', '공격력']
df_character[cols]
# 이때 행에 대한 인덱싱은 불가능하다. > df_character[1] 이런건 불가능
# 아마도 행은 key값이니까 딕셔너리의 key값을 뽑아내는 방식을 떠올려보면 될듯!
# 2. row(행)을 지정해 뽑아내는 방법
df_character[:2]
# 3. 행과 열을 뽑아내는 방법
df_character[cols][:2]
loc, iloc
- loc: 라벨 기반의 인덱싱. 즉 행 또는 열의 이름을 이용해 특정 위치의 행과 열에 접근이 가능하다.
- iloc: 정수 기반의 인덱싱. 즉 정수 인덱스를 이용해 특정 위치의 행과 열에 접근이 가능하디.
우선 loc 부터 보자
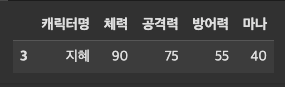
캐릭터명이 ‘지혜’인 데이터 추출
df_characters.loc[df_characters["캐릭터명"] == "지혜"]
각 캐릭터의 ‘마나’ 데이터 추출
df_characters.loc[:,"마나"]

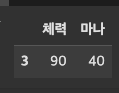
캐릭터명이 ‘지혜’인데, 지혜의 ‘체력’과 ‘마나’데이터만 추출
df_characters.loc[df_characters["캐릭터명"] == "지혜", ["체력", "마나"]]
캐릭터명이 지혜인데, 지혜의 ‘마나’ 데이터만 추출
df_characters.loc[df_characters["캐릭터명"] == "지혜", "마나"]

행의 인덱스 1인 데이터
df_characters.loc[1]

다음은 iloc 예시이다.
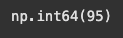
행의 인덱스 3인 데이터
df_characters.iloc[3]
# 지혜의 모든 능력치가 나옴

인덱스 [1,2]인 데이터
df_characters.iloc[1,2]
# 유비의 체력값이 나온다
각 캐릭터의 체력 능력치
df_characters.iloc[:,1]

행의 0번째 인덱스를 제외한 나머지 캐릭터들의 모든 능력치
df_characters.iloc[1:]
연산
덧셈 연산(add)
위 df_character안에 모든 항목에 10을 더해보자
df_character[['체력', "공격력", "방어력", "마나"]].add(10)
df_character
# 혹은
cols = ['체력', "공격력", "방어력", "마나"]
df_character[cols] += 10
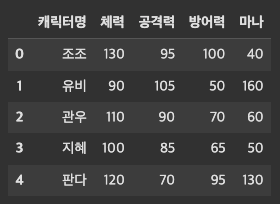
이처럼 모든 항목에 10이 더해진 것을 볼 수 있다.
곱셈 연산(mul)
# 전체 데이터에 곱하기 2
df_character[cols].mul(2)
# 혹은
df_character[cols] *= 2
빼기 연산(sub)
# 전체 데이터에 빼기 10
df_character[cols].sub(10)
# 혹은
df_character[cols] -= 10
합 연산(sum)
# 행의 전체 합 > 모든 능력치의 합을 의미
total = df_character[cols].sum(axis = 1)
나누기(div) & 나머지(mod) 연산
# 나누기
# div(other, axis='columns')
# > 위에서 만든 합에 각 열의 값들을 나눈 값
df_character[cols].div(total, axis=0)
# 나머지
# 3으로 나눴을때의 나머지
df_character[cols].mod(3)
제곱 연산(pow)
# 전체에 2 제곱
df_character[cols].pow(2)
열 추가하기
열을 추가하는 방법은 두가지가 있다.
- 맨 뒤에 연결
- insert
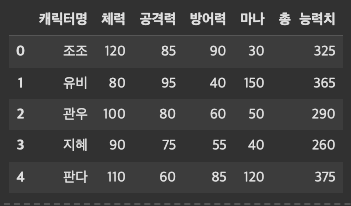
위에서 만든 총 능력치 데이터를 추가해보도록 하자.
# 위에서 만든 총 능력치 데이터
total = df_character[cols].sum(axis = 1)
df_character["총 능력치"] = total
# 원하는 인덱스(=0)에 name과 total 데이터 삽입
df_character.insert(0, "총 능력치", total)
그러다 문득 insert에서 마지막 열에 추가하는 방법이 궁금해져서.. python의 마지막 인덱스처럼 -1로 접근해보니 에러가 뜬다….!
df_character.insert(0, "총 능력치", total)
# ValueError: unbounded slice
그래서 바로 강사님께 여쭤보니 판다스에서는 마지막 요소를 가르키는것이 다르게 동작한다 하셨다. 이때는 len(df_character.columns)를 사용해야한다고.. 직접 column의 개수 그 자체를 인덱스값에 넣어주어야 마지막 인덱스에 데이터 삽입이 가능해진다.
df_character.insert(len(df_character.columns), "총 능력치", total)
둘 다 아주 잘 동작한다!
- max(): 최대값
- min(): 최소값
- mean(): 평균값
- dot(): 행렬곱 연산
- std()표준편차(분산) 계산
- sort_values(‘’, ascending=False): 정렬 > 내림차순
total.sort_values('총능력치', ascending=False)
- date_range(dd, period=, frea=): 날짜모양, 기간, 날짜기준
# 2024-01-01 부터 30 가간을 Day로
pd.date_range('2024-01-01', periods=30, freq='D')
head, tail
- head(*): 첫 *만큼의 데이터 확인
- tail(*): 끝 *만큼의 데이터 확인
df_character.head(3)
df_character.tail(3)
prod
데이터 프레임 내 값들의 곱을 구함 (내용 설명 필요 > 추후 추가 예정)
fillna
데이터 프레임에서 발생되는 결측치(NaN or None값들) 값을 다른 값으로 채우는데 사용
즉, 결측치를 대체하거나 채울값을 지정해줄 수 있다. 수많은 데이터를 다루다보면 어떤 값에는 NaN or None이라는 값이 반환되는 경우가 존재할텐데 이때 여기에 들어갈 값을 내가 지정해줄 수 있다는 의미이다.
df_character_zero = df.fillna(0)
위와 같은 코드를 보자면, df_character_zero라는 임의의 변수안에는 NaN or None값이 포함된 데이터들이 존재한다고 하자. 그때 NaN or None한 데이터에는 내가 지정한 0이라는 값으로 대체되어 데이터가 채워져 보일 것이다.
아, 번외로 계속 헷갈리게 쓰는것 같다.
column은 열이고row가 행이다
groupby
그룹별로 묶어 연산이 가능
# 와인의 종류별로(type) 퀄리티(quality) 컬럼의 평균 구하기
wine.groupby('type')['quality'].mean()
외에도 describe(), std() ,count() 등 다양한 연산이 가능하다. 이때 각 연산들을 한꺼번에 보는 방법도 있다.
wine.groupby('type')['quality'].agg(['mean', 'std'])
위처럼 agg함수를 통해 가능하다.