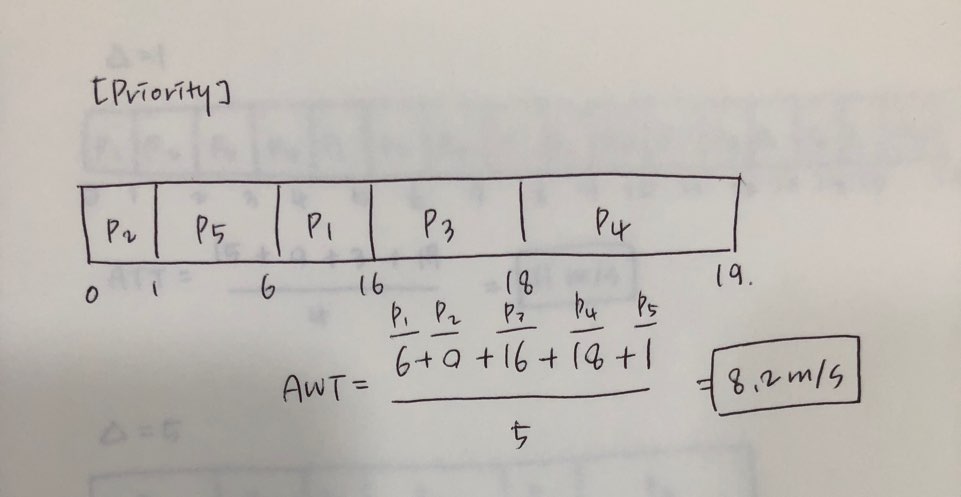
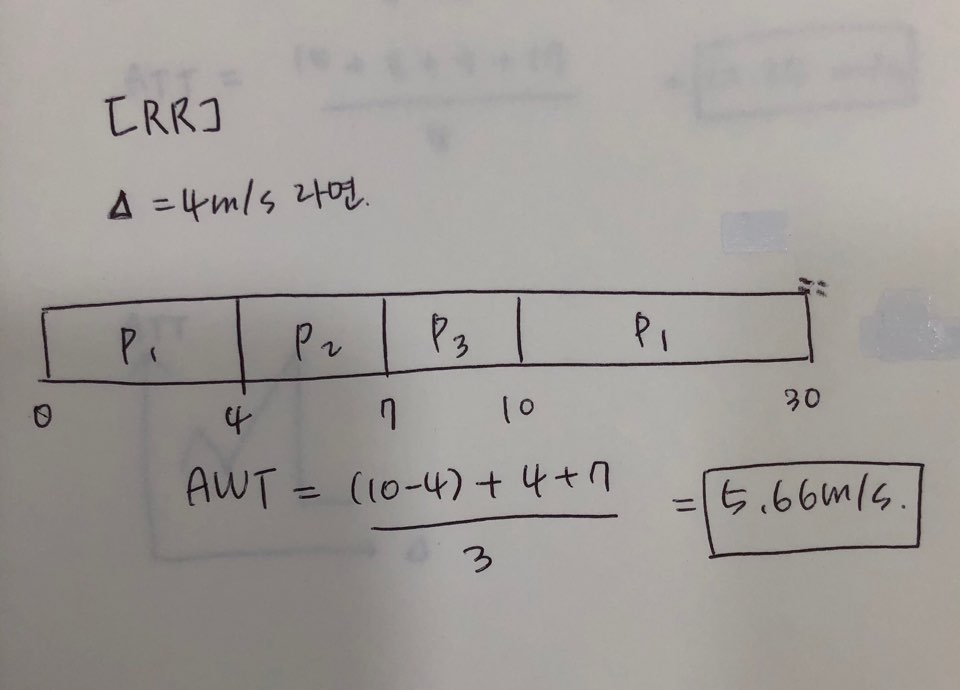
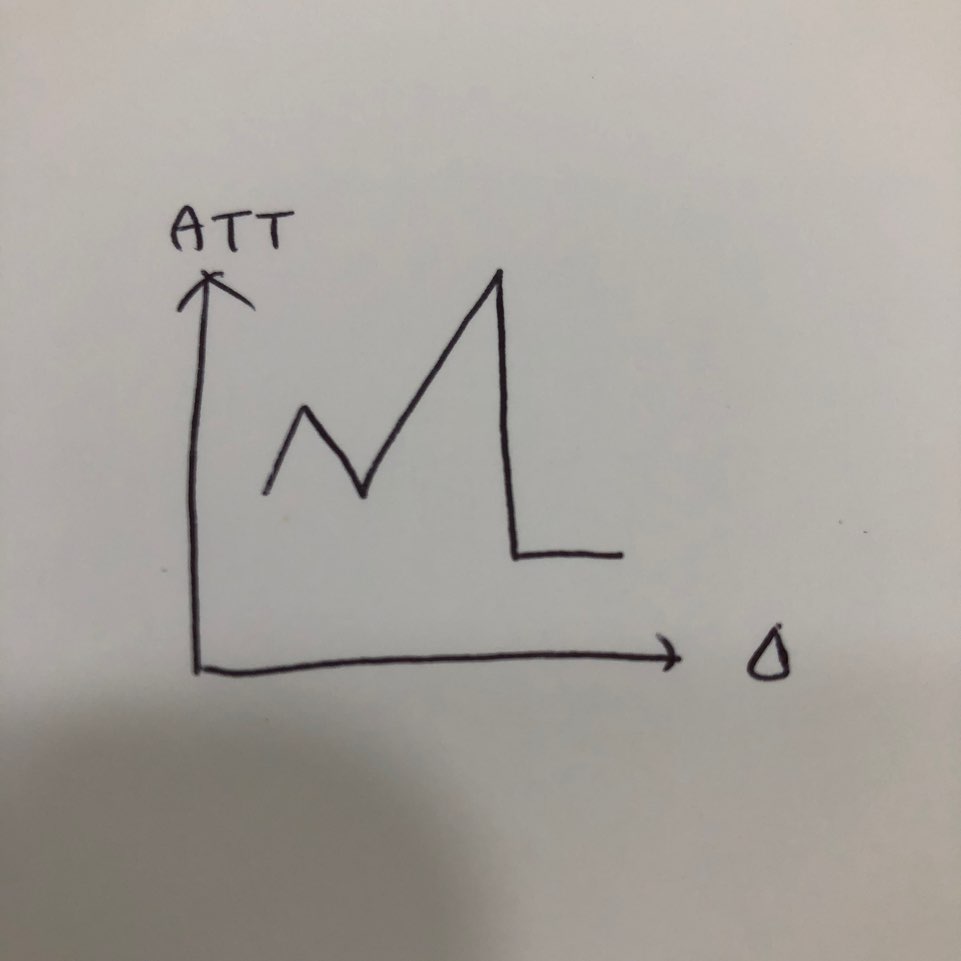
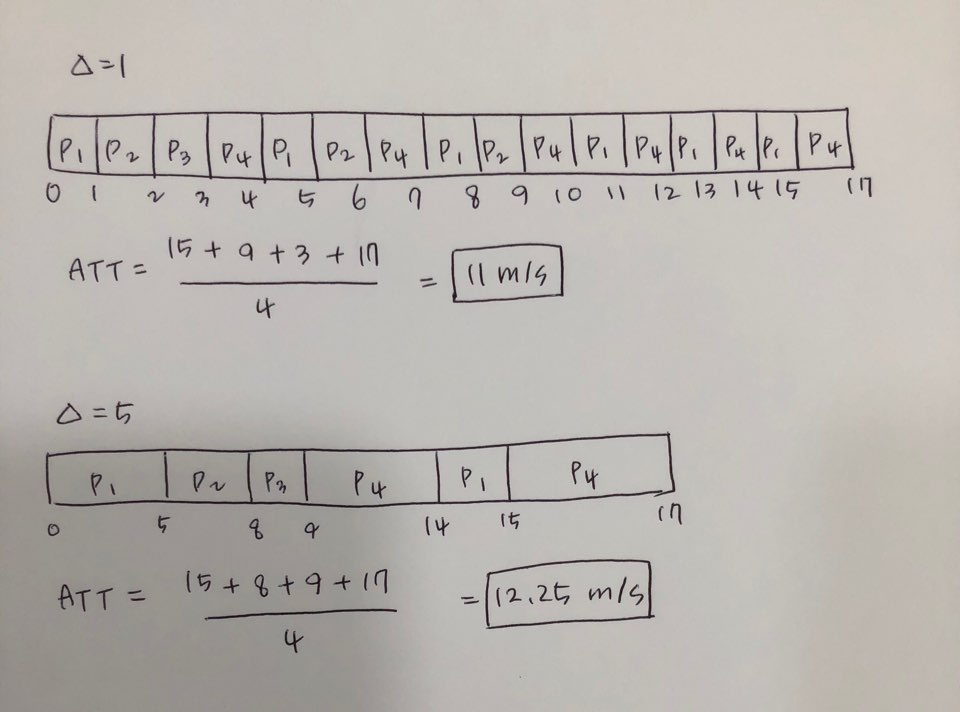
지혜의 개발공부로그
지혜의 개발공부로그
쓰레드(Threads)와 동기화(Synchronization)
06 Dec 2019 | OS operating system개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
경성대학교 양희재 교수님 수업 영상을 듣고 정리하였습니다.
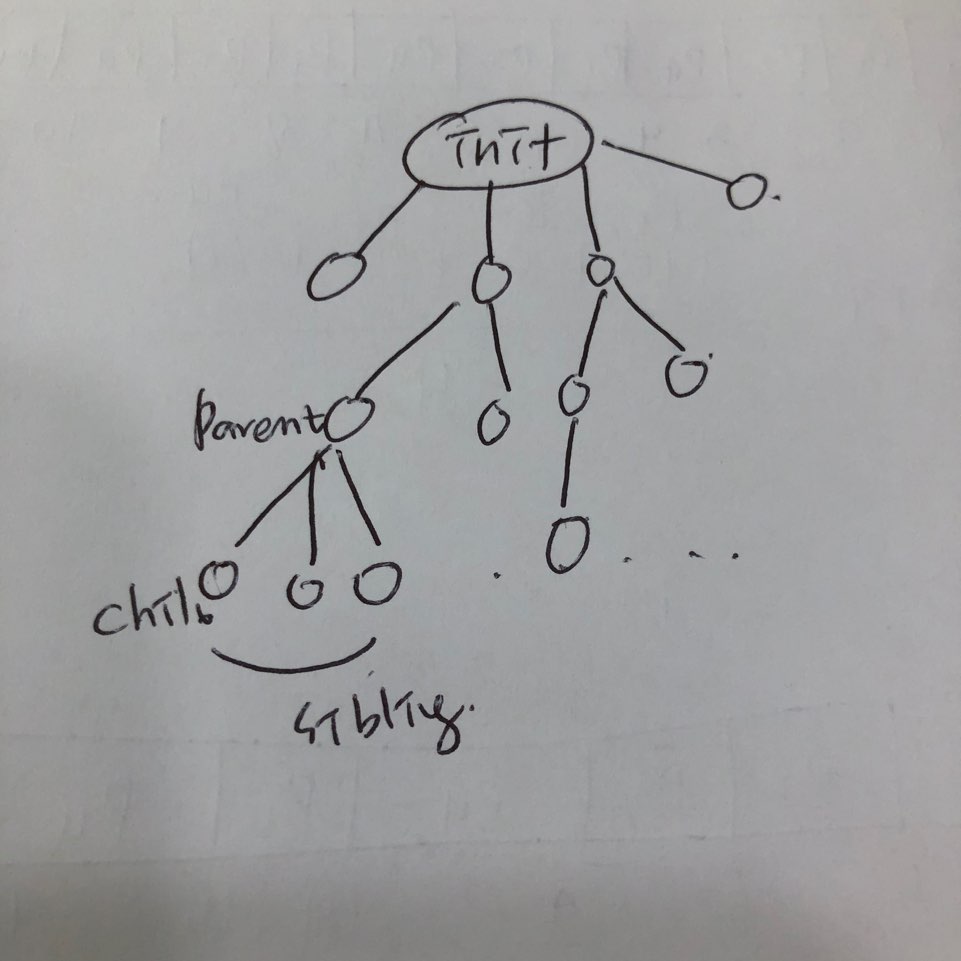
쓰레드 (Thread)
프로그램 내부의 흐름, 맥
class Test {
public static void main(Sting[] args) {
int n = 0;
int m = 6;
System.out.println(n+m);
while (n < m)
n++;
System.out.println("Bye");
}
}
하나의 프로그램은 하나의 맥이 있고 이러한 맥을 쓰레드라고 한다.
Multithreads
- 다중 쓰레드(Multithreads)
- 한 프로그램에 2개 이상의 맥
- 맥이 빠른 시간 간격으로 스위칭 된다 => 여러 맥이 동시에 실행되는 것처럼 보인다. (
concurrentvs simultaneous) - 현재의 모든 프로그램들은 다 다중쓰레드를 지원한다.
동시에 돌 수 있는 이유는 맥이 빠른시간으로 스위칭 되기 때문이다.
그래서 실제로 같이 하고 있는 것처럼 보이지만 사실 CPU는 하나이기 때문에 우리는 하나만 사용하고 있다. 우리는 일반적으로 concurrent!
- 예: Web breoser
- 화면 출력하는 쓰데르 + 데이터 읽어오는 쓰레드
- 예: Word Processor
- 화면 출력하는 쓰레드 + 키보드 입력 받는 쓰레드 + 철자/문법 오류 확인 쓰레드
- 예: 음악 연주기, 동영상 플레이어, Eclipse IDE…
실제 context switching 되는 단위는 process단위가 아니라 thread단위이다!
Thread vs Process
- 한 프로세스에는 기본 1개의 쓰레드: 단일 쓰레드(single thread) 프로그램
-
한 프로세스에 여러개의 쓰레드: 다중 쓰레드 (multi-thread) 프로그램
- 쓰레드 구조
- 하나의 프로그램에서 맥이 여러개다.
- 프로세스의 메모리 공간을 공유한다 (code, data를 쓰레드가 서로 공유)
- 프로세스의 자원공유(한 쓰레드 안에서 file, io 등을 공유)
- 비공유: 개별적인 PC(program counter), SP(stack pointer), Registers, stack
- CPU가 p1에 있는 각각의 쓰레드가 가지고 있는 PC값은 다를 것이다. 그래서 스위칭 될때마다 각자가 가리키고 있는 값이다르니 이 값들은 공유하지 않는다.
- 스택은 리턴값 혹은 파라미터 값을 저장하기 위해 사용되는데, 서로간에 호출하는 메소드가 다 다를수가 있다.
하나의 프로그램은 코드, 데이터, 스택으로 구성되는데 쓰레드가 코드, 데이터는 공유를 하지만 이때 스택은 따로 가지고 있다.
-
- 프로세스의 스위칭 vs 쓰레드의 스위칭
- 현대의 모든 운영체제는
context switching 단위가 쓰레드간의 단위이다.
예: 자바 쓰레드
- 맥 만들기
- java.lang.Thread
- 자바에서는 쓰레드가 객체로 이루어져있기 때문에, 쓰레드라는 객체를 만들어줘야함
- 쓰레드가 가지고 있는 주요 메소드
- public void(run): 새로운 맥이 흐르는 곳
- void(start): 쓰레드 시작 요청
- void(join): 쓰레드가 마치기를 기다림
- static void(sleep): 쓰레드 잠자기 / 멈추도록
- java.lang.Thread
java.lang.Thread
- Thread.run()
쓰레드가 시작되면 run()메소드가 실행된다(run()메소드를 치환한다)
run()안에서 안에서 새로운 맥이 실행되기 때문에 run()을 치환해야 하고, 치환하려면 쓰레드 클래스에 하위 클래스를 만들어서 치환한다.
class MyThread extends Thread{
public void run() { // 치환(override)
// 코드
while (True) {
System.out.println("B");
try {
Thread.sleep(100);
} catch (InterruptedException e) ()
}
}
}
class Test {
public static void main(String[] args) {
MyThread th = new MyThread()
th.start();
while (True) {
System.out.println("A");
try {
Thread.sleep(100);
} catch (InterruptedException e) ()
}
}
}
- 모든 프로그램은 처음부터 1개의 쓰레드는 갖고 있다(main)
- 2개의 쓰레드: main + MyThread
해당 프로그램이 시작되면 main함수가 먼저 시작할것이다. main함수의 MyThread가 실행되면서 while문의 무한루프가 돌면서 B가 계속해서 찍혀나갈 것이고 그와 동시에 main함수의 while문이 무한루프를 돌면서 A를 계속해서 찍어낼 것이다. 컴파일해보면 A와 B가 섞여서 찍힐 것이다.
프로세스 동기화(Process Synchronization)
더 정확한 표현은 Thread Synchronization이다.
서로간 영향을 주고받는 데이터들간에 데이터의 일관성이 유지될 수 있도록 해주는 것이 동기화이다.
보통 컴퓨터 메모리 안의 프로세스들은 독립적이지 않고 협조하는 관계이다. 즉, 다른 프로세스에게 영향을 주거나 영향을 받는다. 대부분 공통된 자원(메인메모리)을 서로 접근하려고 하다보니 그런것이다. 하나의 메인메모리에 프로세스들이 많으니 어떤 방식으로든 영향을 주고받으니 그럴수록 프로세스 동기화의 개념이 중요해지고 있다.
- Processes
- Independent vs Cooperating
Cooperating process: one that can affect or be affected by other processes executed in the system(그 시스템 내에서 실행되고 있는 다른 프로세스에 대해서 프로세스 간 영향을 주든지 영향을 받든지하는 프로세스)- 프로세스 간 통신: 전자우편, 파일 전송(서로 공유하며 데이터 통신을 함)
- 프로세스간 자원 공유: 메모리 상의 자료들, 데이터베이스 등(데이터를 공유하기에 서로에게 영향을 줌)
- 명절 기자표 예약, 대학 온라인 수강신청, 실시간 주식거래
- Process Synchronization
- Concurrent access to shared data may result in data inconsistency
- Orderly execution of cooperating processes so that data consistency is maintained
-> 공유 데이터에 동시에 접근하면 데이터의 비일관성을 초래한다.
-> 서로간 영향을 주고받는 데이터들간에 데이터의 일관성이 유지될 수 있도록 해주는 것이 동기화이다.
- ex: BankAccount Problem(은행계좌문제)
- 부모님은 은행계좌에 입금, 자녀는 출금
- 입금(deposit)과 출금(withdraw)은 독립적으로 일어난다.
class BankAccount {
int balance;
void deposit(int n) {
balance = balance + n;
}
void withdraw(int n ){
balance = balance + n;
}
int getBalance() {
return balance;
}
}
class Parent extends Thread {
BankAccount b;
Parent(BankAccount b) {
this.b = b;
}
public void run() {
for (int i=0; i<1000;, i++)
b.deposit(1000);
System.out.println("+");
}
}
class Child extends Thread {
BankAccount b;
Child(BankAccount b) {
this.b = b;
}
public void run() {
for (int i=0; i<1000;, i++)
b.withdraw(1000);
System.out.println("-");
}
}
class Test {
public static void main(String[] args)
throws InterruptedException {
BankAccount b = new BankAccount();
Parent p = new Parent(b);
Child c = new Child(b);
p.start();
c.start();
p.join();
c.join();
System.out.println("balance = " + b.getBalance());
}
}
잔액은 0원이 나올 것이다.
프로세스 동기화가 안되는 경우의 문제
시간지연에 따라 잘못된 결과를 초래한다.
class BankAccount {
int balance;
void deposit(int n) {
balance = balance + n;
System.out.println("+");
balance = temp;
}
void withdraw(int n ){
balance = balance + n;
System.out.println("-");
balance = temp;
}
int getBalance() {
return balance;
}
}
class Parent extends Thread {
BankAccount b;
Parent(BankAccount b) {
this.b = b;
}
public void run() {
for (int i=0; i<1000;, i++)
b.deposit(1000);
}
}
class Child extends Thread {
BankAccount b;
Child(BankAccount b) {
this.b = b;
}
public void run() {
for (int i=0; i<1000;, i++)
b.withdraw(1000);
}
}
class Test {
public static void main(String[] args)
throws InterruptedException {
BankAccount b = new BankAccount();
Parent p = new Parent(b);
Child c = new Child(b);
p.start();
c.start();
p.join();
c.join();
System.out.println("balance = " + b.getBalance());
}
}
시간지연에도 불구하고 결과는 바르게 나와야하는데, 이를 해결해야하는 것을 동기화라고 한다.
-> context switching이 중간에 일어나게 되면 이상한 결과를 초래할 수 있다.
-> 공통변수(common variable, balance)에 대한 동시 업데이트(concurrent update)로 인해 발생!
(즉, 하이레벨 랭귀지는 한줄이지만 로우레벨은 여러줄인데 업데이트 도중에 스위칭이 발생)
-> 해결: 공통변수에 대해 한번에 한 쓰레드만 업데이트 하도록한다! 임계구역 문제 = atomic하게!
임계구역 문제(Critical-Section Problem)
Critical section(임계구간, 치명적인 구간): 이 구간에서 아주 치명적인 오류가 발생할 수 있다.
A system consisting of multiple threads. Each thread has a segment of code, called critical section, in which the thread may be changing common variables, updating a table, writing a file, and so on
여러개의 쓰레드로 구성된 시스템에서 각각의 쓰레드는 어떤 코드의 영역을 가지고 있는데, 그 코드의 영역을 임계구역이라고 한다. 이 임계구역이 되기 위해서는 여러 쓰레드들이 공통의 변수, 테이블, 파일들을 바꾸는 부분 코드를 임계구역이라고 한다.
- Solution (3개가 모두다 만족되어야 한다.)
-
Mutual exclusive(상호배타): 오류가 일어나지 않으려면 공통 변수에 대한 업데이트는 오직 한 쓰레드만 들어가 있을 때 진행되어야 한다. 즉 Parent가 critical section에 들어가면 그 순간에는 Child가 critical section에 들어가면 안된다.
-
Progress(진행): 진입 결정은 유한 시간 내에 일어나야 한다. 즉 critical section에 누가 들어갈 것인지를 결정하는 것은 유한 시간 내에 일어나야 한다.
-
Bounded waiting(유한대기): 어느 쓰레드라도 유한 시간 내에 일어나야 한다. 기다리는 시간의 한계가 들어가 있다는 것으로 내가 기다리고 있다면 유한 시간 내에 critical section 안으로 들어갈 수 있다.
-
프로세스/쓰레드 동기화
- 임계구역 문제 해결
- 프로세스 실행 순서 제어(원하는대로)
- Busy wait 등 비효율성 제거
프로세스 관리에서 중요한 것은 결국 프로세스/쓰레드의 동기화이다. 틀린답이 나오지 않도록 os에서 임계구역 문제를 해결해줘야 한다. 그리고 프로세스/쓰레드의 순서를 임의로 제어할 수 있어야 한다.