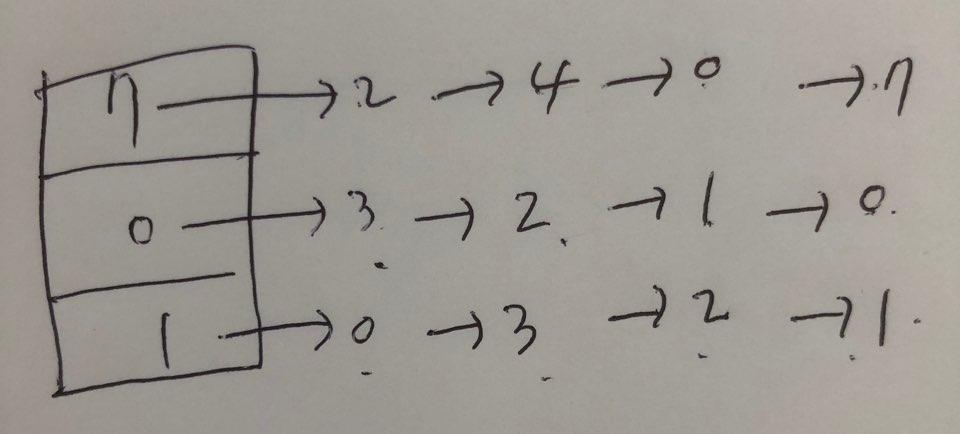지혜의 개발공부로그
지혜의 개발공부로그
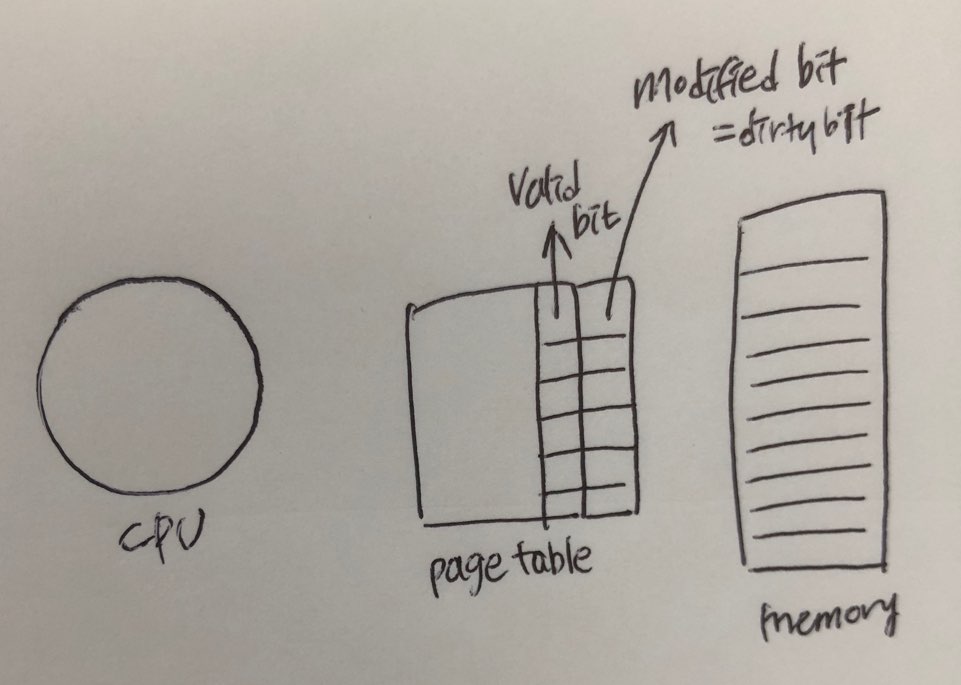
프레임 할당(Allocation of Frames)
24 Dec 2019 | OS operating system개인공부 후 자료를 남기기 위한 목적임으로 내용 상에 오류가 있을 수 있습니다.
경성대학교 양희재 교수님 수업 영상을 듣고 정리하였습니다.
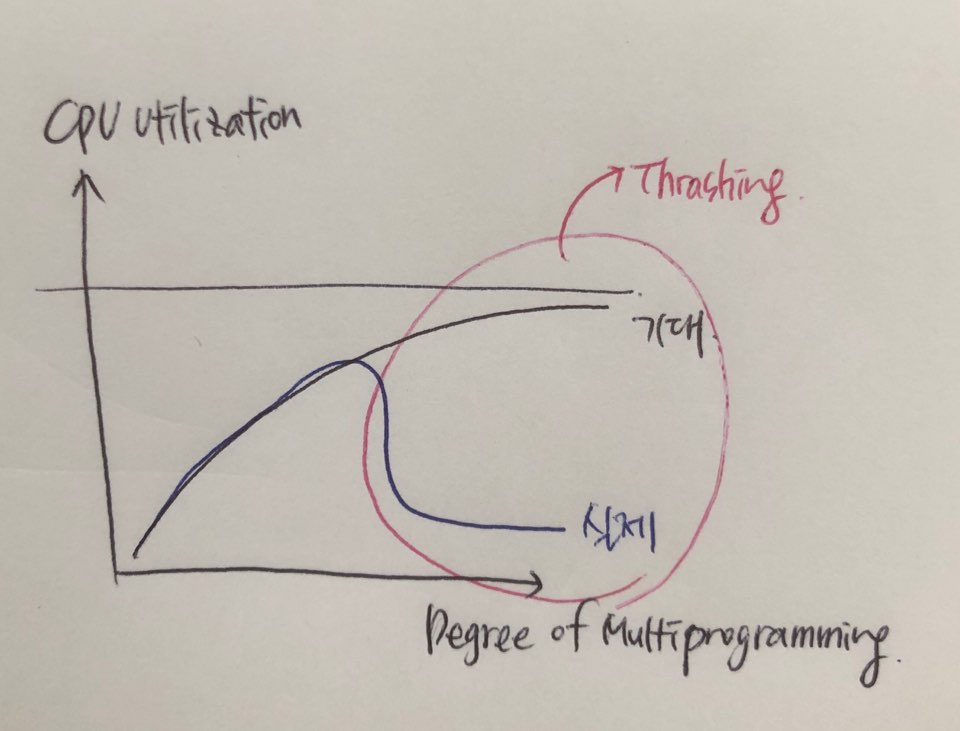
쓰레싱(Fhrashing)
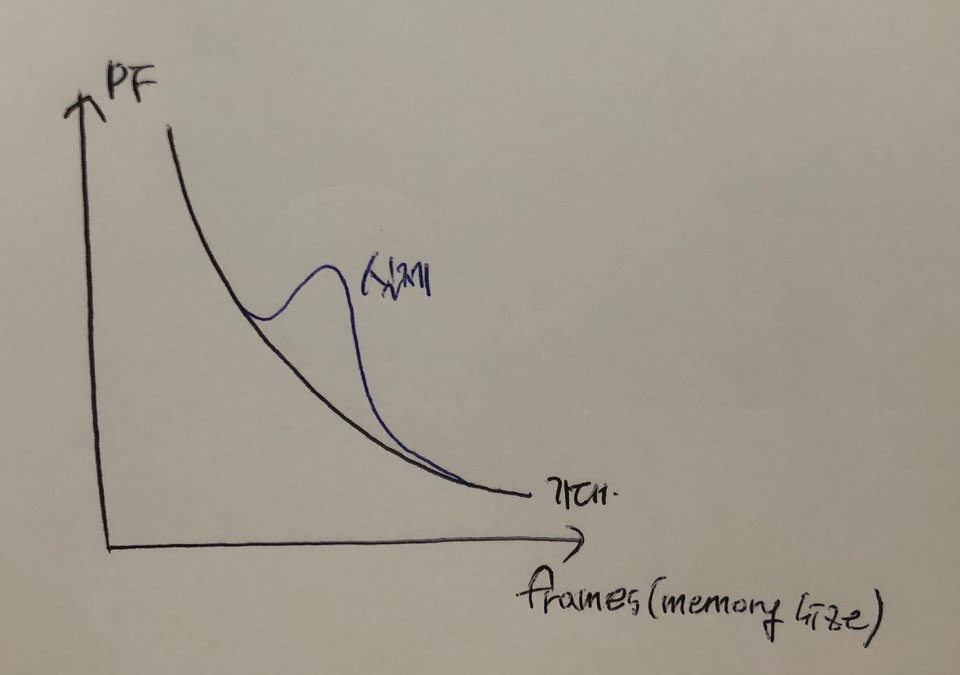
page fault가 너무 자주일어나는 것을 쓰레싱이라고 한다.
- cpu utilization vs Degree of multiprogramming(cpu이용률 vs 메인메모리에 올라온 프로세스의 수)
- 프로세스 개수 증가 > cpu 이용률 증가
- 일정 범위를 넘어서면 cpu 이용률 감소
- 이유: 빈번한 page in/out
- Thrashing: i/o 시간 증가 때문
- 쓰레싱 극복
- Global replacement 보다는
local replacement - 프로세스당 충분한/적절한 수의 메모리(프레임) 할당
- Global replacement 보다는
프레임 할당(Allocation of Frames)
어떤 프로세스에게 얼마만큼의 프레임을 할당해줄 것인가를 결정
- 정적할당(static allocation): 프로세스를 실행해보지않고 프로세스 사이즈만 보고 결정
- 균등할당(Equal allocation): 모든 프로세스에게 동일한 비율로 할당
- 비례할당(Proportional allocation): 용량이 클수록 비례하게 할당
- 동적할당(dynamic allocation): 실제 실행을 해보고 결정
- Working set model
- Page fault frequency
- etc
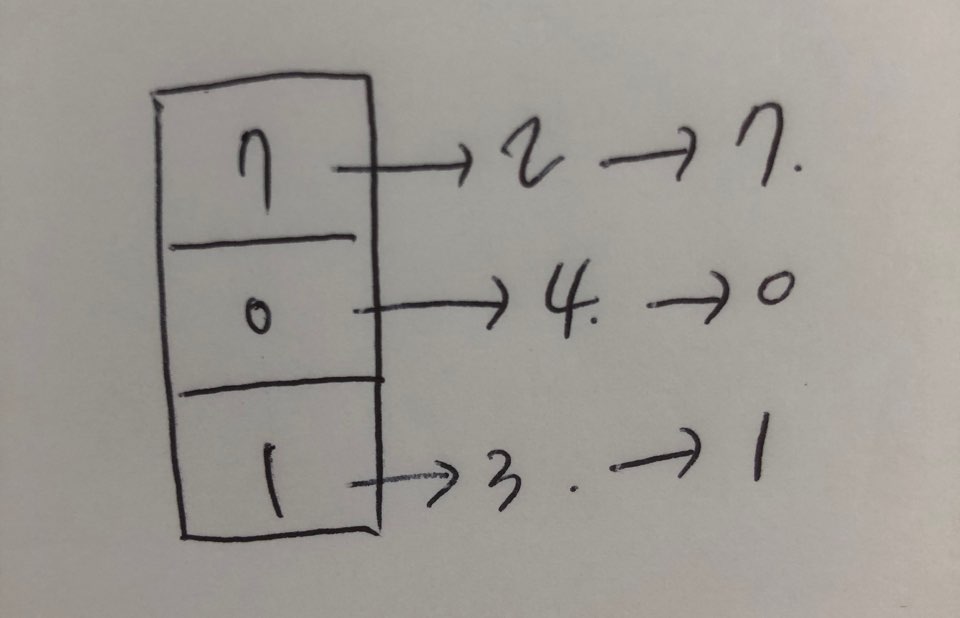
Working set model
- Locality vs working set
- Locality: 페이지들이 모여있는 것 (cpu가 내는 주소는 모여져있다.)
working set: 과거 일정 시간대에 사용된 페이지
Working set window(=Δ): 현 시점을 기준으로 얼마를 과거로 보는지에 대한 시간- Working set 크기 만큼의 프레임 할당
Locality만큼 프레임을 할당해주면 좋겠지만, 미래의 Locality를 알수가 없기때문에 과거에 참조했던 페이지,
즉 과거는 얼마만큼 과거나면 working set window seconds 이는 os를 만든사람이 결정한다.
과거 사용된 페이지(working set)만큼을 할당해준다. 그렇게 되면 쓰레싱이 발생하지도 않으면서 메모리를 너무 낭비하지도 않을 것이다.
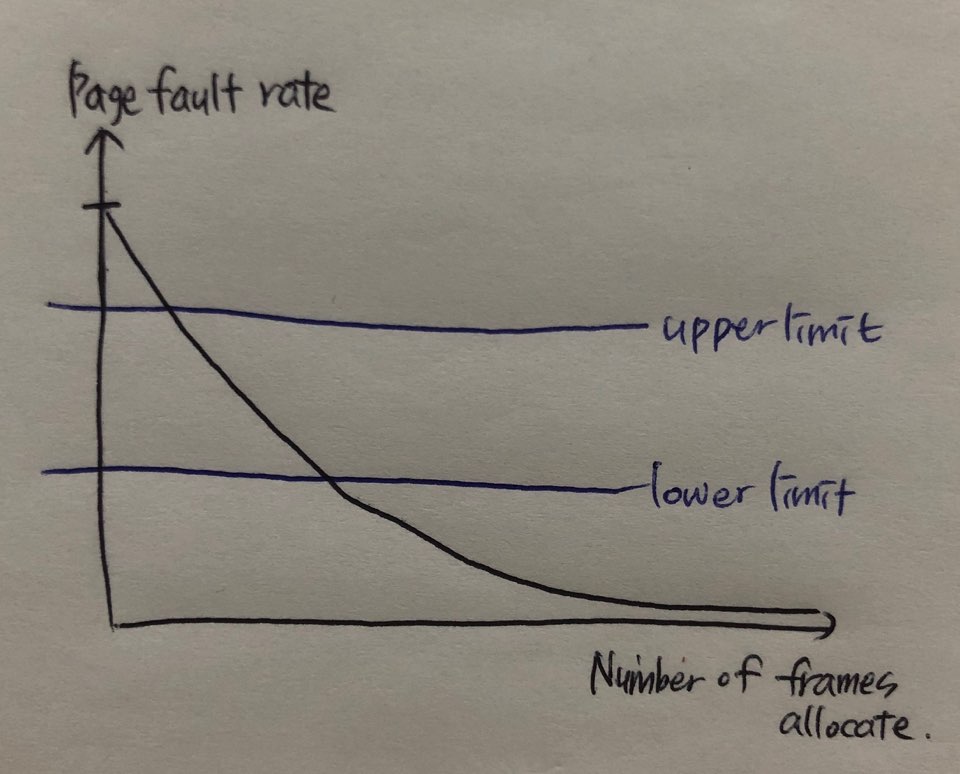
Page-Fault Frequency(PFF)
- Page fault 발생 비율의 상한/하한선
- 상한선 초과 프로세스에 더 많은 프레임 할당
- 하한선 이하 프로세스의 프레임은 회수