당신은 우주 탐사선 ‘노바-1’의 통신 장교입니다. 그런데 외계 신호의 공격으로 인해 동료들과의 통신 암호가 뒤죽박죽이 되어버렸습니다! 암호를 원래대로 복구하여 긴급 메시지를 해독해야 합니다. 암호는 단어의 순서가 거꾸로 뒤집혔고, 특정 글자가 다른 글자로 바뀌었습니다.
defdecode_message(sentence):foriinsentence:ifi=='@':sentence=sentence.replace('@','e')elifi=='#':sentence=sentence.replace('#','i')elifi=='$':sentence=sentence.replace('$','o')elifi=='%':sentence=sentence.replace('%','u')# sentence를 ,구분자로 나누고 []배열안에 넣기
sentence=sentence.split()# 역순으로 넣은 후 배열에서 스트링으로
return' '.join(sentence[::-1])decode_message("w@lc$m@! t$ pyth$n #s h@ll$!")
<2. 교육 내 답변>
defdecode_message(encoded_str):# 1. 암호를 단어 단위로 분리합니다.
words=encoded_str.split(' ')# 2. 단어의 순서를 거꾸로 뒤집습니다.
words.reverse()decoded_words=[]print(decoded_words)forwordinwords:# 3. 각 단어의 특수문자를 알파벳으로 바꿉니다.(메서드 체이닝 활용)
temp_word=word.replace('@','e').replace('#','i').replace('$','o').replace('%','u')decoded_words.append(temp_word)# 4. 해독된 단어들을 다시 하나의 문장으로 합칩니다.
return" ".join(decoded_words)# 예시 실행
encoded_message="w@lc$m@! t$ pyth$n #s h@ll$!"decoded_message=decode_message(encoded_message)print(f"암호: {encoded_message}")print(f"해독: {decoded_message}")
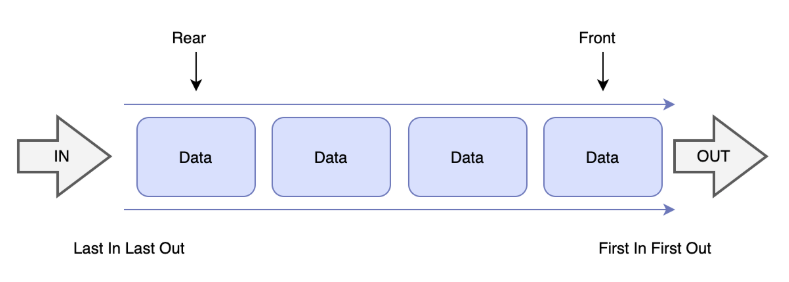
선형 자료구조 중에서도 동적 자료구조에 해당하는 Queue는 필요에 따라 메모리에 공간을 유연하게 할당하고 해제해 데이터를 저장할 수 있어 데이터의 추가, 삭제, 크기 변경등이 가능하다. 이때 스택의 가장 중요한 특징은 FIFO 개념이다.
FIFO: First In First Out
먼저 들어온 데이터가 먼저 나가는 자료구조
선착순의 원리 > 먼저 들어온 사람이 먼저 서비스를 받음
스택과 반대되는 개념
주요 연산
Enqueue(인큐): queue의 뒤쪽(rear) 데이터에 삽입
Dequeue(디큐): queue의 앞쪽(front) 데이터 삭제 및 반환
Python으로 구현해보는 queue
classQueue:def__init__(self):# queue를 담아줄 빈 리스트 생성
self.items=[]# 맨 앞의 인덱스 0 지정
self.front_index=0defenqueue(self,value):# items안에는 일단 차곡차곡 데이터가 쌓인다
self.items.append(value)defdequeue(self):try:# items이 빈리스트가 아니라면 (값이 있다면)
returnself.items.pop(0)exceptIndexError:# items에 아무것도 없다면 더이상 삭제할 아이템이 없으니까 indexError발생
print('Queue is empty')returnNone
각 연산들의 시간 복잡도: O(1) 인 것도 확인 가능하다. (enqueue, dequeue)
Enqueue
리스트의 append 함수 사용
항상 리스트의 끝에 데이터가 추가됨
Dequeue
리스트의 pop 함수 사용
항상 리스트의 맨 앞 데이터가 삭제됨
collections의 deque를 사용해도 됨
큐 예제 > 조세푸스(josephus)
문제 상황
N명이 원형으로 앉아있음
K번째 사람마다 제거
마지막 남은 1명의 번호 찾기
case1, 그냥 풀어보기
defjosephus(n,k):queue_list=[]foriinrange(1,n+1):# 1부터 n까지 큐에 enqueue
queue_list.append(i)# 2. 반복:
# - (k-1)개는 dequeue 후 다시 enqueue
# - k번째는 dequeue만 (제거)
# 3. 큐에 1개만 남을 때까지 반복
whilelen(queue_list)>1:foriinrange(k-1):queue_list.append(queue_list.pop(0))queue_list.pop(0)# 4. 마지막 남은 번호 반환
returnqueue_listjosephus(6,2)
case2, deque 활용해서 풀어보기
fromcollectionsimportdeque# deque 사용해보기
defjosephus(n,k):dq=deque()foriinrange(1,n+1):# 1부터 n까지 큐에 enqueue
dq.append(i)# 2. 반복:
# - (k-1)개는 dequeue 후 다시 enqueue > k-1: 앞에서 몇번 건너뛸지
# - k번째는 dequeue만 (제거)
# 3. 큐에 1개만 남을 때까지 반복
whilelen(dq)>1:foriinrange(k-1):dq.append(dq.popleft())dq.popleft()# 4. 마지막 남은 번호 반환
returndqjosephus(6,2)
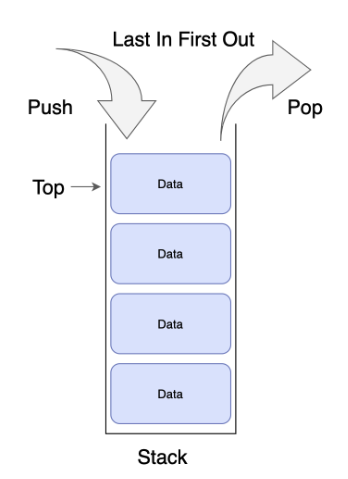
선형 자료구조 중에서도 동적 자료구조에 해당하는 Stack은 필요에 따라 메모리에 공간을 유연하게 할당하고 해제해 데이터를 저장할 수 있어 데이터의 추가, 삭제, 크기 변경등이 가능하다. 이때 스택의 가장 중요한 특징은 LIFO 개념이다.
LIFO: Last In First Out
가장 마지막에 들어온 데이터가 가장 먼저 나가는 자료구조
데이터는 한쪽 끝에서만 삽입, 삭제가 이루어짐
중간에 대한 접근은 불가능 > 오직 맨 위(top) 데이터에만 접근 가능
주요 연산
push(value): 스택의 맨 위에 값을 추가 > append개념
pop: 스택의 맨 위 값만 제거하고 반환
Python으로 구현해보는 stack
classStack:def__init__(self):# stack을 담아줄 빈 리스트 생성
self.items=[]defpush(self,value):# 비어있는 stack에 값을 추가
self.items.append(value)defpop(self):try:# items이 빈리스트가 아니라면 (값이 있다면)
returnself.items.pop()exceptIndexError:# items에 아무것도 없다면 더이상 삭제할 아이템이 없으니까 indexError발생
print('Stack is empty')returnNonedeftop(self):# 현재 스택 최상단 친구는 누구인지 묻는 함수
try:returnself.items[-1]exceptIndexError:# items에 아무것도 없다면 더이상 삭제할 아이템이 없으니까 indexError발생
print('Stack is empty')returnNone# 이미 존재하는 함수인 len 접근
def__len__(self):returnlen(self.items)
각 연산들의 시간 복잡도: O(1)인 것도 확인 가능하다.(push, pop, top, len)
스택 예제 > 괄호 맞추기
문제 상황
왼쪽 괄호 ‘(‘ → 스택에 push
오른쪽 괄호 ‘)’ → 스택에서 pop
모든 괄호 처리 후 스택이 비어있으면 올바른 쌍
defcheck_parentheses(seq):# 위에서 만들어놓은 Stack 클래스를 통해 stack 객체 생성
stack=Stack()forsinseq:# 들어온 seq에 s가 "(" 라면
ifs=="(":# stack에 ( 를 추가 (push)
stack.push(s)# 들어온 seq에 ")"라면
elifs==")":# 현재 stack의 길이를 확인해서
# 길이가 0이면 현재 스택엔 아무것도 없다는 뜻이니까
iflen(stack)==0:# 비어있다고 출력
# 근데 원래는 )가 있었어야해 ()이렇게가 쌍이니까!
# 그래서 다르게 표현해보면 > return False 이것도 맞다
return"empty stack"# 만약 stack이 비어있지 않다면? -> 길이가 0이 아니라면
# (든 )든 둘중 뭐가 있다는 뜻이니까 일단 맨끝에 있는 애를 삭제해! (pop)
stack.pop()# for문을 통해 들어온 seq에 대한 push, pop을 다 진행한 뒤에 stack의 길이를 확인
# pop을 했는데 stack의 길이가 0보다 많다면 ()의 쌍이 맞지 않았다는 뜻이니까
iflen(stack)>0:# 쌍이 잘 맞지 않았고, stack은 비어있지 않다는 의미!
return"not empty"# len == 0이라는 의미는 쌍이 맞았다는 의미니까
return"잘 넣으셨군요"
자료구조에서 재귀란 함수의 실행 과정에서 자기 자신을 한번 이상 호출하는 함수를 의미한다.
defsum_n(n):ifn==1:return1returnsum_n(n-1)+n
이 함수를 실행시켜보면 sum_n(4) > sum(3) + 4 > sum(2) + 3 > sum(1) + 2 > 1으로 진행될 것이다.
수행시간은 T(n) = T(n-1) + C (C는 상수) > T(n-2) + C + C > T(n-3) + C + C + C ... > C*N(=T1~Tn)으로 시간복잡도는 O(n)임을 알 수 있다.
재귀함수의 주의점
기본케이스(base case)를 반드시 만들어야한다.
recursive call이 반드시 있어야한다.
기본 케이스란 재귀 호출을 수행하지 않는 반환값을 의미한다. 위 코드에서 기본케이스는 if n == 1: return 1를 의미한다. 즉, 함수가 반복적으로 호출되었을때 제일 마지막 호출에서는 기본 케이스가 돌아야한다. 그렇지 않으면 코드는 무한반복으로 자기 자신을 호출하기 때문에 함수가 끝나지 않게된다. 파이썬에서의 while True를 떠올리면 이해가 쉽다.
그리고 재귀함수는 반드시 자기 자신을 한번 이상 호출해야한다. 위 코드에서는 return sum_n(n-1) + n에 해당한다.
이러한 재귀함수는 for,while문을 호출하지 않기에 좀 더 코드가 간결해진다는 장점은 존재하지만, 이러한 재귀호출이 많아지면 질수록 메모리의 효율은 떨어진다는 단점 또한 존재한다.
다수의 데이터프레임(DataFrame) 혹은 시리즈(Series)를 결합하는 방법에 대해 정리해본다.
pd.concat() > 데이터프레임 붙이기
데이터프레임을 말그대로 물리적으로 이어붙여주는 함수 > pd.concat(데이터프레임 리스트)로 사용
importpandasaspd# df1, df2 데이터 프레임을 각각 만들어 주면서 각각의 index를 지정해줌
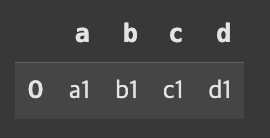
df1=pd.DataFrame({'a':['a0','a1'],'b':['b0','b1'],'c':['c0','c1']},index=[0,1])df2=pd.DataFrame({'a':['a1','a2','a3'],'b':['b1','b2','b3'],'c':['c1','c2','c3'],'d':['d1','d2','d3']},index=[1,2,3])
pd.concat()의 axis는 디폴트 0로 지정되어있기 때문에 둘의 합쳐진 방향이 아래로 이어붙여짐을 알 수 있다.(axis=0은 열기준, 위아래) 그리고 df1의 c는열은 존재하지 않기 때문에 c에 해당하는 데이터가 NaN으로 채워진것 또한 볼 수 있다. 그리고 더 나아가 데이터프레임을 붙일때 그냥 이어붙이다보니 인덱스 번호도 그대로 붙여진 것을 볼 수 있다. 이때는 ignore_index=True를 하면 인덱스 재배열이 가능하다.
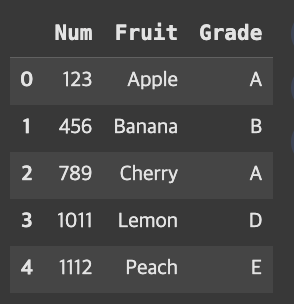
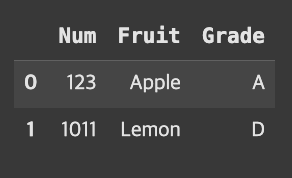
아무 옵션을 적용하지 않으면, on=None이기에 두 데이터의 공통된 열인 Num과 Grade를 기준으로 교집합인 데이터가 반환된다.
result=pd.merge(fruit,grade)result
여기서 pd.merge(fruit, grade)는 pd.merge(fruit, grade, on=[‘Num’,’Grade’])와 동일하다.
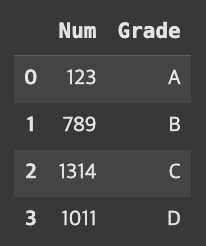
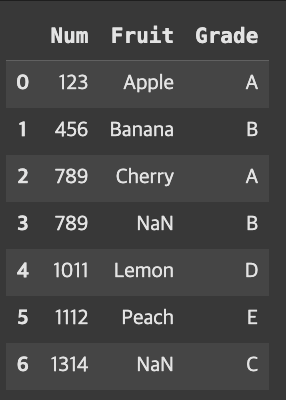
pd.merge(fruit, grade, how=’outer’)의 경우
merge()의 how는 inner(교집합)가 디폴트이기때문에 outer(합집합)인 경우를 보겠다.
result=pd.merge(fruit,grade,how='outer')result
Grade에 존재하지 않았던 Fruit 값은 NaN으로 들어가있음을 볼 수 있고, 공통적으로 있던 값은 하나로 합쳐져 출력된 것을 볼 수 있다.
pd.merge(fruit, grade, how=’left or right’)
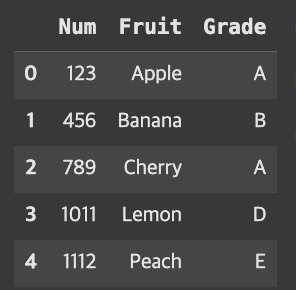
how=’left’
result=pd.merge(fruit,grade,how='left')result
fruit에 관한것만 나오는것을 볼 수 있다. 그 이유는 pd.merge(fruit, grade, how=’left’)에서 데이터프레임의 순서가 fruit, grade 순서로 병합해준 것이기 때문이다. 따라서 왼쪽에 위치만 fruit에 관련된 데이터만 출력된 것을 볼 수 있다.
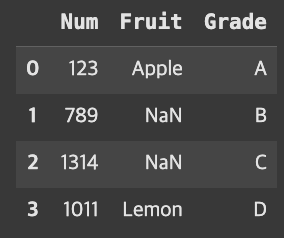
how=’right’
result=pd.merge(fruit,grade,how='right')result
여기서도 마찬가지로 grade에 관련된 데이터만 나왔고, 비어있는 값에 대해서는 NaN으로 출력되어있다.
열을 지정해주는 경우
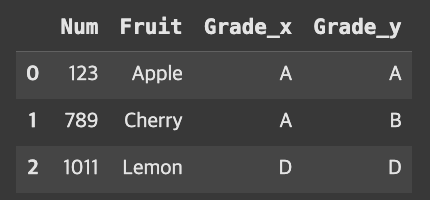
result=pd.merge(fruit,grade,on='Num')result
공통된 열 중에 Num 하나만 지정해주는 경우 재밌는 결과가 나온다.
Num을 기준으로 Fruit 데이터가 나오고 그에 대한 fruit, grade의 Grade 데이터가 나왔다.

 지혜의 개발공부로그
지혜의 개발공부로그