importnumpyasnp# 넘파이
importpandasaspd#pandas
fromsklearn.model_selectionimporttrain_test_split#데이터 분리
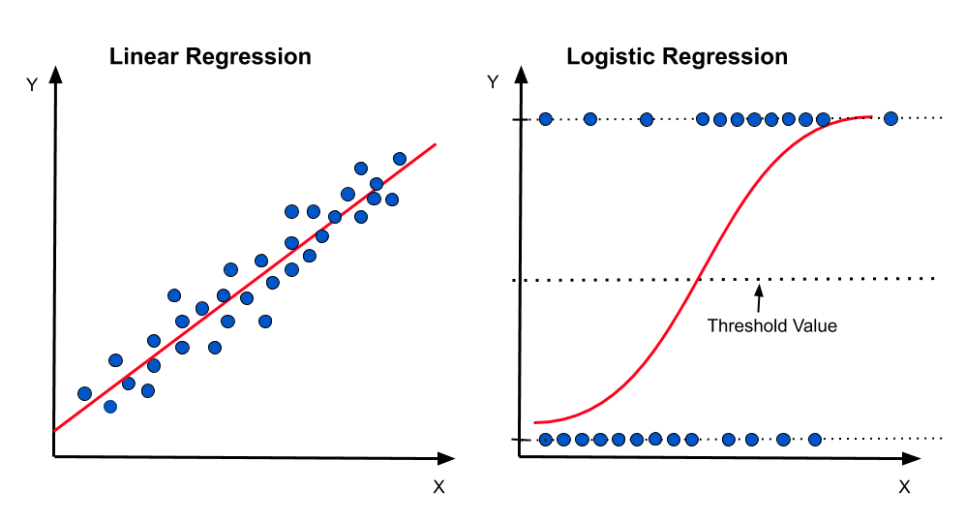
fromsklearn.linear_modelimportLogisticRegression#LogisticRegression 로지스틱 회귀모델
fromsklearn.preprocessingimportStandardScaler#StandardScaler 데이터 정규화
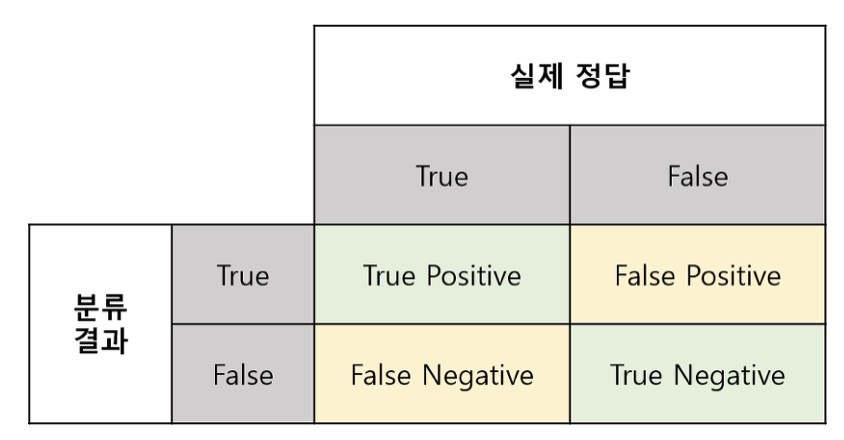
fromsklearn.metricsimportaccuracy_score,confusion_matrix,classification_report#범주형에 따른 새로운 매트릭
importmatplotlib.pyplotasplt#시각화
importseabornassns#시각화
데이터 불러오기
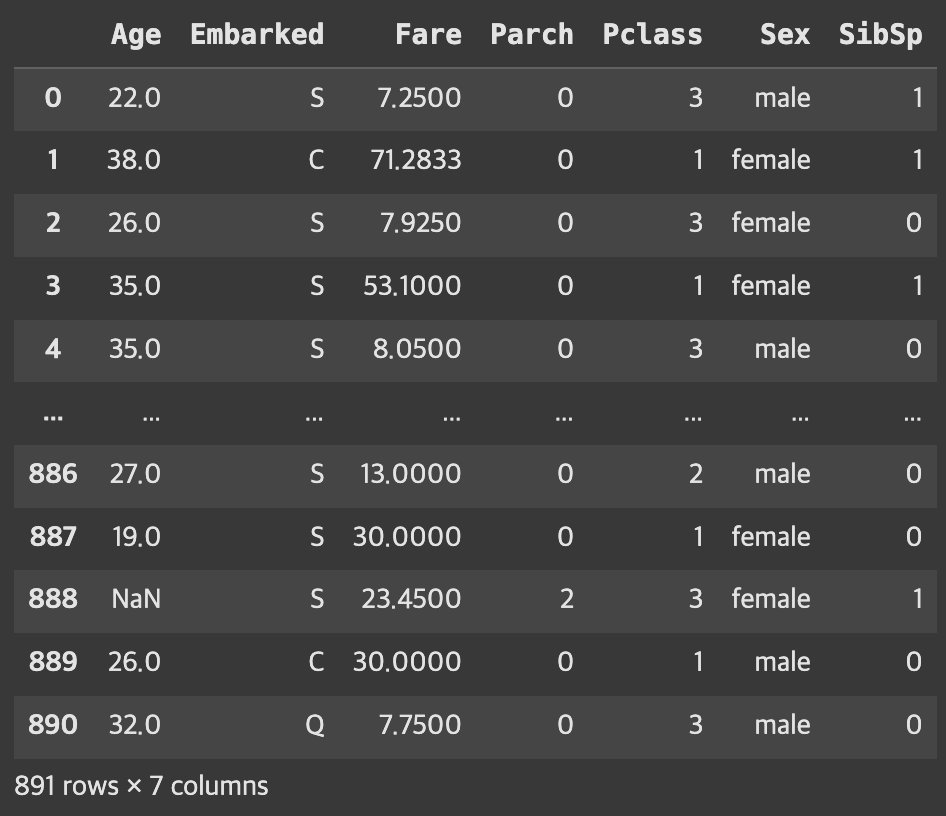
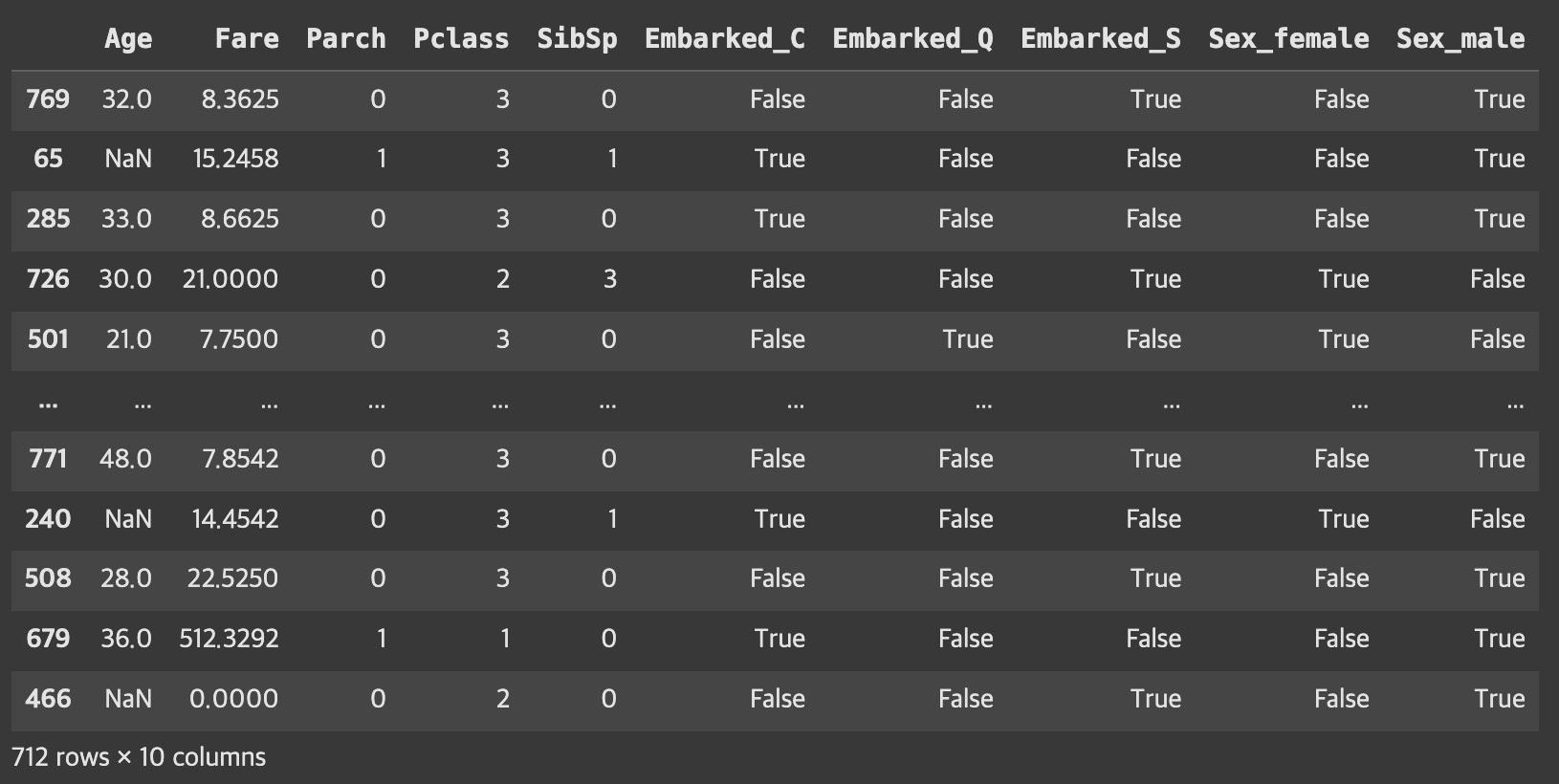
train=pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/titanic/train.csv')test=pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/titanic/test.csv')target='Survived'# difference > 필요없는 컬럼들 빼줌 / 따라서 feature안에는 필요한 애들만 들어가있는 것!
features=train.columns.difference(['Survived','PassengerId','Name','Ticket','Cabin'])X=train[features]y=train[target]# 교안이 잘 만들어짐! > X!
# 스케일링은 X만 스케일하기 때문에 대부분 X랑 y로 분할 한다음에 X만 스케일링 함
X
데이터 전처리 - 원 핫 인코딩
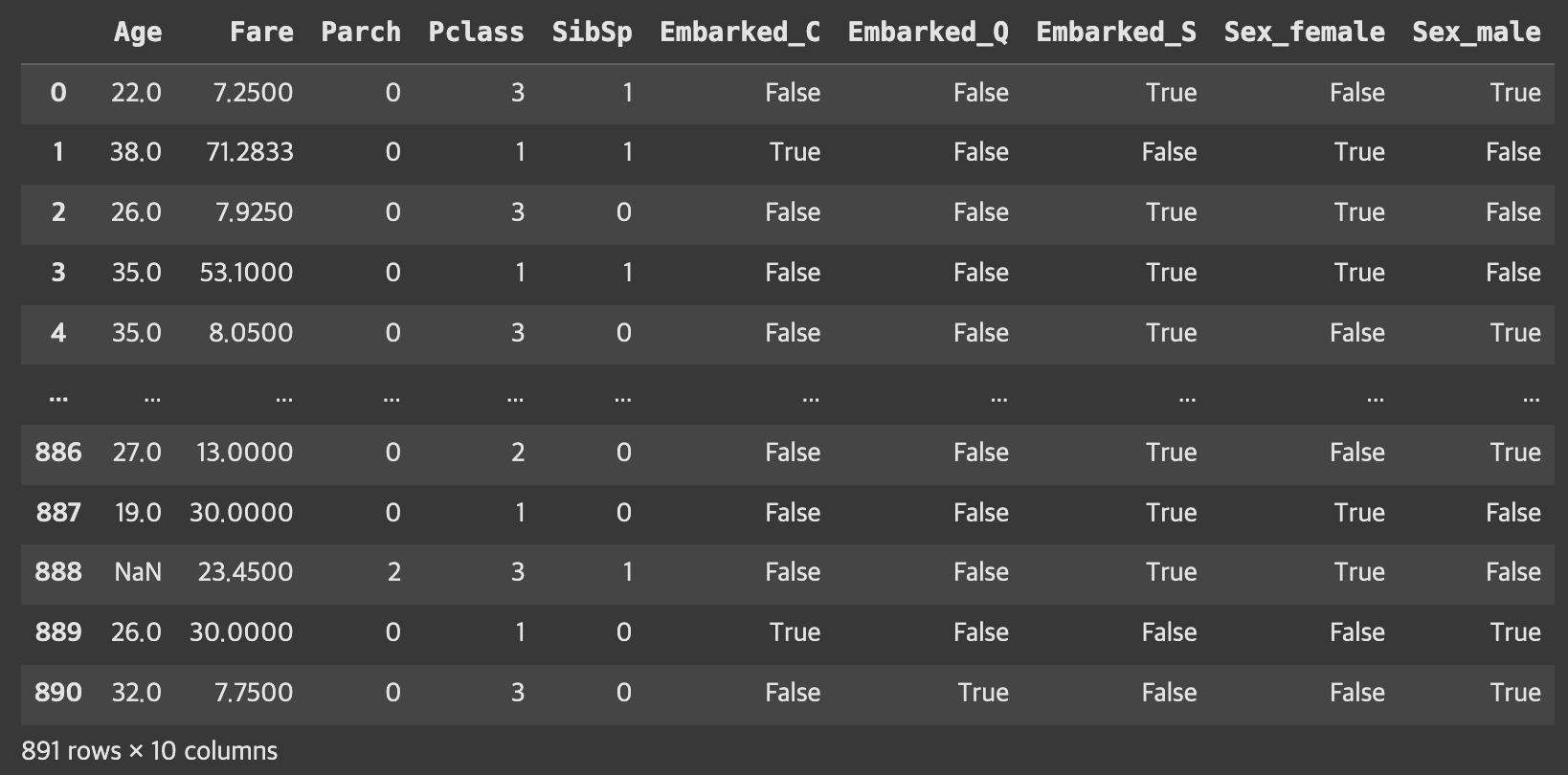
fromsklearn.preprocessingimportOneHotEncoder# get dummies를 쓰거나 scikit-learn 를 쓰거나 둘 중 하나를 선택
X=pd.get_dummies(X)#, drop_first=True)
X
데이터 분할
# 위에서 만든 교안 X은 0,1로 바꿔진 상태인데 80% train, 20% test로 분리하겠다는 뜻 !
X_train,X_val,y_train,y_val=train_test_split(X,y,test_size=0.2)X_train
결측값 처리 > sklearn
fromsklearn.imputeimportSimpleImputer# 훈련된 train 데이터에 결측값이 있을 수 있음!
# > pandas에서 처리할지 sklearn에서 처리할지는 알아서 선택!
# strategy='mean': 결측값을 자동으로 찾아 평균값을 넣어주는 것 > 다 수치형이나까 평균값을 넣어도 됨
imputer=SimpleImputer(strategy='mean')X_train_imputed=imputer.fit_transform(X_train)X_val_imputed=imputer.transform(X_val)
특성 스케일링
fromsklearn.preprocessingimportStandardScaler# 특성이란 것이 feature > 컬럼값이라는 뜻인데
# 표준편차에 집어넣어서 다 0+-a로 바꾸게 됨
# 이 특성 스케일링을 지나고 나서 남는 최종 결과물은 0.~ 1.~ 이런식으로 표준화된 값이 나옴
# 기존 데이터들이 다 바뀜 > 컴퓨터는 이게 판단하기가 더 쉬움!
# 즉, 각기 다른 수치들의 단위를 맞춰주는 것이 스케일링!
scaler=StandardScaler()# 스케일링을 한 데이터로 학습 시켰으니까 모델은 스케일링한 데이터로 학습이 되었겠죠?
# 그렇다면 스케일링을 안한 데이터로 평가를 하면 정확도가 떨어지기 때문에
# 테스트와 훈련 모두 스케일링 처리를 한다~ 고 이해하시면 되요!
# 스케일링 했으면 train과 test 둘다 해줘야함
# 둘다 똑같이 작업한 다음에 비교해줘야함
X_train_scaled=scaler.fit_transform(X_train_imputed)X_val_scaled=scaler.transform(X_val_imputed)
fromsklearn.metricsimportaccuracy_score,precision_score,recall_score,f1_score# y_val: 실제 정답 / y_pred: 예측 값 > 이 둘을 가지고 정확도를 측정해야함!
# y^ 과 y_val 비교
y_pred=model.predict(X_val_scaled)
이 외에도 KNN, 나이브베이즈, SVM, 결정트리, 앙살블(그래디언트 부스트, 랜덤포레스트, 부스팅..), 스태킹..
비지도 학습: y(결과값)가 주어지지 않은 경우
군집 분석
K-means, DBScan, 덴드로그램
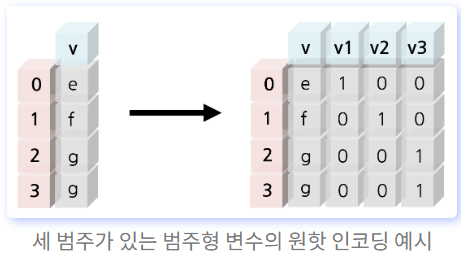
원핫 인코딩(One-Hot Encoding)
표현하고 싶은 단어의 인덱스에 1의 값을 부여하고, 다른 인덱스에는 0을 부여하는 단어의 벡터 표현 방식을 말하며, 이렇게 표현된 벡터를 원-핫 벡터(One-Hot vector)라고 한다.
원핫인코딩 하기에 적합한 경우
데이터가 범주형이어야 함
범주형이더라도 숫자형이면 꼭 할 필요 없고, 문자형일 경우 하면 좋음!
ex) 타이타닉 데이터셋에서
적합한 경우 : sex, embarked
부적합한 경우 : pclass & name
pclass는 범주형이기는 하지만 이미 숫자이기 때문
즉, 변경 여부가 모델학습에 큰 영향을 미치지 않음
pd.get_dummies(df,columns=['sex','embarked'],dtype='int')# pandas 사용
pd.get_dummies(df,columns=['범주형_컬럼'])# scikit-learn 사용
fromsklearn.preprocessingimportOneHotEncoderencoder=OneHotEncoder()encoded=encoder.fit_transform(data)
레이블 인코딩
그 외 대표적인 인코딩 기법에는 레이블 인코딩이 있으며 이는 각 범주에 고유한 정수를 할당하여 숫자로 변환하는 방식을 말한다.
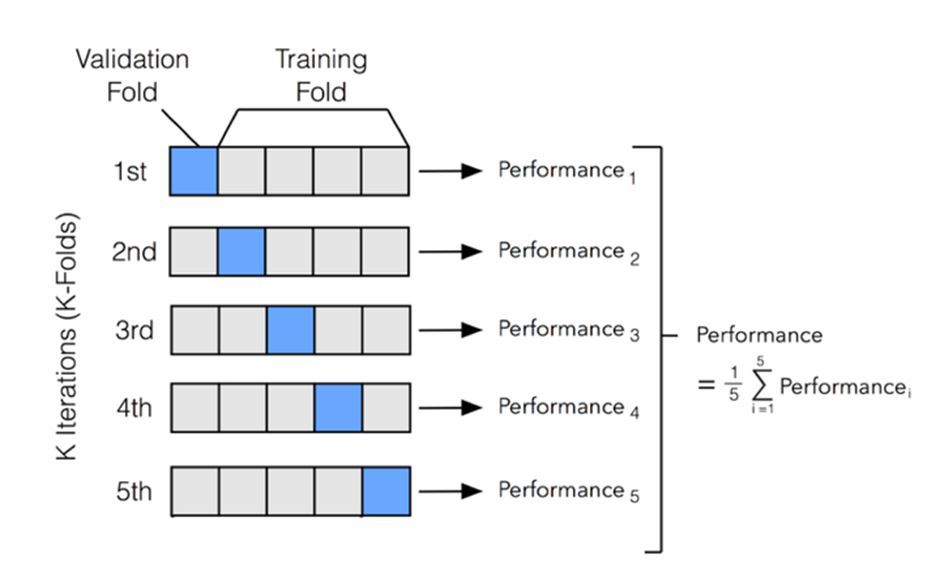
전체 데이터셋을 k개의 fold로 나누어 1개의 fold를 test data로, 나머지 (k-1)개의 foldfmf train data로 분할하는 과정을 반복함으로써 train, test data를 교차 변경하는 방법론
즉, 학습데이터 셋과 검증 데이터 셋을 점진적으로 변경하면서 마지막 k번째까지 학습, 검증을 수행함!
진행순서
데이터 분할(설정할 수 있는 하이퍼파라미터)
반복학습
성능측정: 각 반복에서 검증 성능 측정
각 점수를 평균, 표준편차 계산
이 작업을 왜 하는걸까?
과적합을 줄일 수 있음
측면 반복학습이다 보니 성능이 안정적일 수 있고,
기존 하나의 데이터를 뜯어볼수 있어 데이터 활용이 극대화 됨
구현해보기
# k-fold 라이브러리 불러오기
fromsklearn.model_selectionimportKFold,cross_val_scoredf=pd.read_csv('https://ds-lecture-data.s3.ap-northeast-2.amazonaws.com/house-prices/house_prices_train.csv')X=df[['GrLivArea','LotArea']]y=df['SalePrice']# 선형회귀모델 정의
simple_model=LinearRegression()# 모델 훈련
simple_model.fit(X,y)# n_splits > 5개로 나누고, 섞어줌 (그래서 실행마다 array값이 조금씩 바뀜!)
kf=KFold(n_splits=5,shuffle=True,random_state=42)# 훈련 끝난 데이터, 데이터, y값, scoring=평균으로 계산할지? 표준편차로 계산할지? ,cv=내가 정의한 kfold 정보를 넣으줌
# 사이킷런 규칙으로 MSE는 값을 음수로 반환
# 사이킷런은 모든 평가 점수를 클수록 좋은 점수로 규칙을 맞춰놓음 > 근데 MSE는 작을수록 좋으니 규칙에 맞지않음
MSE_score=cross_val_score(simple_model,X,y,scoring='neg_mean_squared_error',cv=kf)MSE_score# array([-3.38953122e+09, -2.77111324e+09, -4.35654599e+09, -2.90526053e+09, -2.47771029e+09])
# 그래서 임의로 다시 우리가 그 값에 -를 붙여 양수로 반환시킴 > 이게 진짜 우리가 보고싶은 MSE 값임!
-MSE_score.mean()# np.float64(3180032254.0430913)
fromsklearn.linear_modelimportElasticNet# 엘라스틱 모델 정의
elastic_model=ElasticNet(alpha=0.3,l1_ratio=0.5)# 엘라스틱 모델 훈련
elastic_model.fit(X_train,y_train)# 예측
pred_elastic=elastic_model.predict(X_test)# MSE
MSE_elastic=mean_squared_error(y_test,pred_elastic)MSE_elastic# 3389531933.0839124
탁구공, 농구공 등의 데이터가 들어왔을 때, 이것을 공으로 분류해야하지만 동그라미로 분류하게 되면 실제 정답간의 차이가 생기게 된다. 이 차이의 정도를 bias라고 한다.
Variance
모델의 variance가 낮다 = 모델의 복잡도가 낮다
모델의 variance가 높다 = 모델의 복잡도가 높다
동그란 것을 공으로 분류한다고 생각해보자. 이때는 동그랗다는 특징만 가지고 있기 때문에 탁구공, 농구공의 문양과 같은 국소적인 특징에는 집착하지 않아도 된다. 따라서 탁구공, 농구공에 대해 모델이 비슷한 값을 출력할 것이다. 즉, variance가 낮게 나올 것이다.
즉, 우리가 ‘공’이라고 분류하고 싶은 데이터에 대해서 모델이 출력하는 값 또한 ‘공’으로 비슷할 것
그러나 동그랗고, 맨들거리고 등등과 같은 다양한 특징을 공을 분류하기 위해 사용한다면 탁구공, 농구공에 대해 모델의 값이 많이 달라질 것이다. 농구공은 겉이 꺼끌거리지만 탁구공은 부드럽기 때문에 같은 공임에도 불구하고 예측값이 다르게 나올 것 이다. 즉. variance가 높게 나올 것이다.
데이터를 ‘공’으로 분류하고 싶지만 추가적인 특징들이 모델을 다른 공으로 분류하도록 할 수 있음
따라서 같은 공을 분류함에도 어떤 특징을 사용하느냐에 따라 예측값의 퍼져있는 정도, 데이터셋의 예민한 정도가 다 다르다. 이러한 것을 측정하는 데에 사용하는 것이 variance이다.
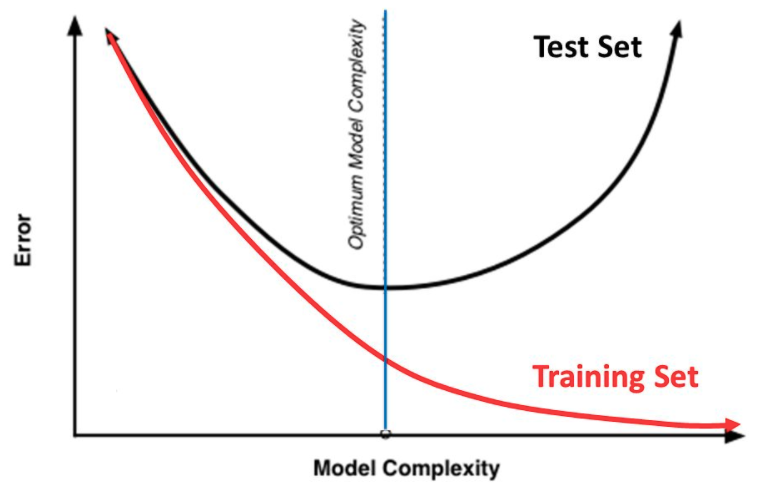
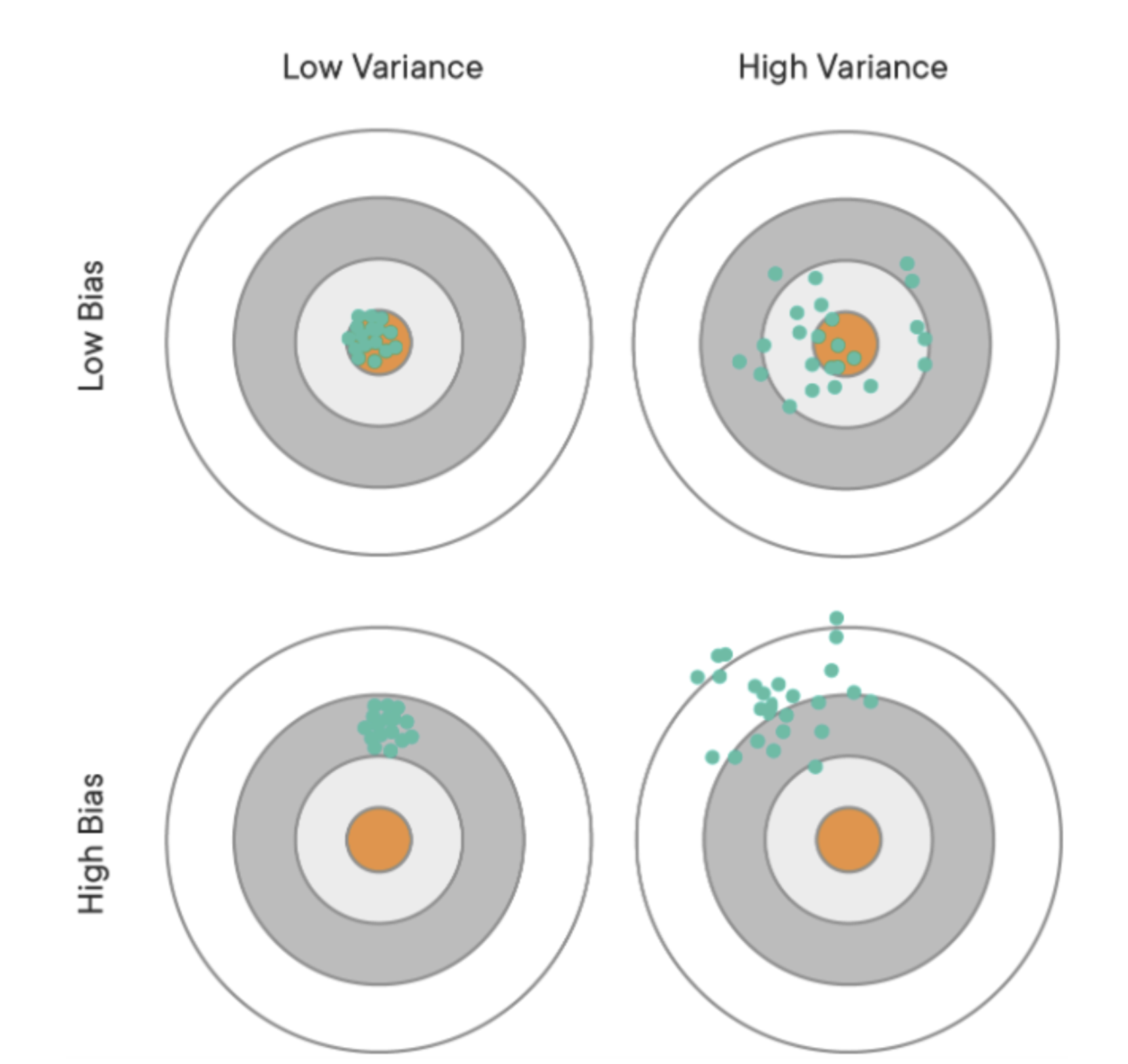
위 그림은 train, test 데이터에 대한 결과를 bias, variance 관점에서 해석한 그림이다. 이는 MSE 수식을 통해 바라볼 수 있다.
가운데 주황색 동그라미 영역은 target으로, 정답&참값을 의미함
초록색 점들은 모델이 예측한 값을 의미함
Low Bias & Low Variance (좌상단): 실제 정답과 예측 값들의 차이가 적고, 예측값들의 variance도 낮아서 loss가 낮은 모델이다. 모든 데이터셋에서 이러한 경향을 보인다면 학습이 잘 되었다고 볼 수 있다.
Low Bias & High Variance (우상단): 예측한 값을 평균한 값은 정답과 비슷한데, 예측값들의 variance가 높아 loss가 높은 모델아다.
High Bias & Low Variance (좌하단): 예측값들의 variance는 낮지만 실제 정답과의 차이가 큰 경우로 학습이 잘 안 된 경우로 볼 수 있다.
High Bias & High Variance (우하단): Bias와 Variance 둘 다 높아 학습이 잘 안 된 경우이다.

 지혜의 개발공부로그
지혜의 개발공부로그