서브쿼리는 WHERE, SELECT, FROM, HAVING절 안에 넣어 사용할 수 있고, 이러한 서브쿼리는 괄호안에 적어주어야 한다. 일반적으로 서브쿼리가 먼저 실행된 후 메인쿼리가 실행되는 순서로 작업이 이루어진다.
조건절에서 사용하는 서브쿼리
-- 문제: 고객 전체의 평균 마일리지보다 평균마일리지가 큰 도시에 대해-- 도시명과 도시의 평균 마일리지를 보이시오SELECT도시,AVG(마일리지)평균마일리지FROM고객GROUPBY1HAVINGAVG(마일리지)>(SELECTAVG(마일리지)FROM고객);
INLINE VIEW
FROM 절에서 사용하는 서브쿼리
이때 뷰에는 별명을 지정해줘야하며, 인라인뷰의 별명은 테이블명처럼 사용가능하다.
-- 문제: 담당자명, 고객회사명, 마일리지, 도시, 해당도시의 평균 마일리지를 보이시오-- 그리고 고객이 위치하는 도시의 평균 마일리지와 각 고객의 마일리지 간 차이도 함께 보이시오SELECT담당자명,고객회사명,마일리지,고객.도시,도시_평균마일리지,(도시_평균마일리지-마일리지)차이FROM고객,(SELECT도시,AVG(마일리지)as'도시_평균마일리지'FROM고객GROUPBY1)as도시별요약WHERE고객.도시=도시별요약.도시;
Scalar SubQuery(스칼라서브쿼리)
SELECT 절에서 사용하는 서브쿼리
서브쿼리의 값이 딱 1개의 값으로 도출되어야 하는 서브쿼리로 이 쿼리를 통해 반환되는 값을 메인쿼리에서 사용한다. 이때 서브쿼리의 결과로 행을 0개 반환한다면 메인쿼리의 결과는 null이고 2개 이상의 행이 반환된다면 오류가 발생한다.
-- 문제1: 고객번호, 담당자명과 고객의 최종 주문일을 보이시오SELECT고객번호,담당자명,(SELECTMAX(주문일)최종주문일FROM주문WHERE고객.고객번호=주문.고객번호)AS최종주문일FROM고객;
CTE(Common Table Expression)
쿼리로 만든 임시데이터셋으로 WITH에서 정의
쿼리 내에서 여러번 참조가 가능하기때문에 재사용성이 좋으며, 하나의 쿼리를 논리적 블록으로 나눌 수 있어 가독성이 좋다.
-- 문제: 담당자명, 고객회사명, 마일리지, 도시, 해당도시의 평균 마일리지를 보이시오-- 그리고 고객이 위치하는 도시의 평균 마일리지와 각 고객의 마일리지 간 차이도 함께 보이시오-- 이를 CTE로 풀이하시오 SELECT담당자명,고객회사명,마일리지,고객.도시,도시_평균마일리지,(도시_평균마일리지-마일리지)차이FROM고객,(SELECT도시,AVG(마일리지)as'도시_평균마일리지'FROM고객GROUPBY1)as도시별요약WHERE고객.도시=도시별요약.도시;-- CTEWITH도시별요약AS(SELECT도시,AVG(마일리지)AS도시_평균마일리지FROM고객GROUPBY1)SELECT담당자명,고객회사명,도시_평균마일리지,(도시_평균마일리지-마일리지)차이FROM고객,도시별요약WHERE고객.도시=도시별요약.도시;
하나의 테이블에 원하는 데이터가 모두 있다면 좋겠지만, 두 개의 테이블을 엮어야 원하는 결과가 나오는 경우도 많다. 이때 조인을 쓰면 두개의 테이블을 엮어 원하는 데이터를 추출할 수 있게 한다. 즉 조인이란,
두 개 이상의 테이블을 연결하여 데이터를 검색하는 방법
서로 다른 테이블에 저장된 데이터를 함께 가져와 하나의 결과로 표시함
검색하고 싶은 컬럼이 서로 다른 테이블에 있을 때 사용
조인을 사용해 여러개의 테이블을 마치 하나의 테이블처럼 사용 가능
조인 방식
ANSI SQL
FROM 절 안의 두 테이블 사이에 조인 종류(CROSS, INNER, OUTER)에 따라 JOIN 키워드를 넣어줌
ON 절에 조인에 대한 조건을 작성하고 나머지 조건은 WHERE 절에 작성
CROSS, INNER, OUTER 키워드는 생략 가능
Non-ANSI SQL
FROM 절에 테이블을 쉼표로 구분해 작성
조인조건, 기타조건을 구분없이 WHERE절에 작성
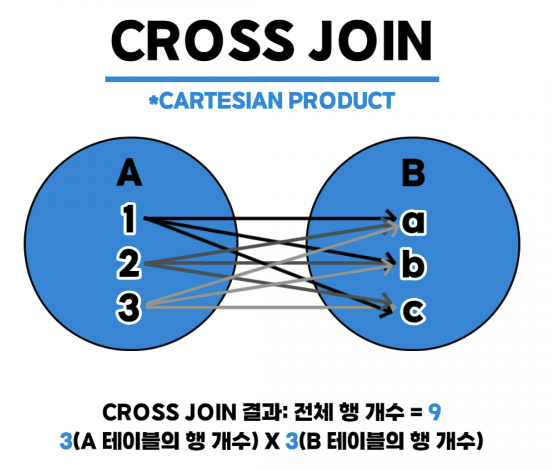
CROSS JOIN
한 쪽 테이블의 각 행마다 다른 쪽 테이블의 모든 행이 각각 한번씩 매칭되는 조인 (Cartesian Product)
-- 문제1: 사원테이블과 부서테이블을 조인하여 배재용 사원에 대한 정보를 보이시오-- 이름, 사원테이블의 부서번호, 부서테이블의 부서번호, 부서명SELECT사원.이름,사원.부서번호,부서.부서번호,부서.부서명FROM사원JOIN부서ON사원.이름='배재용';SELECT사원.이름,사원.부서번호,부서.부서번호,부서.부서명FROM사원,부서WHERE사원.이름='배재용';
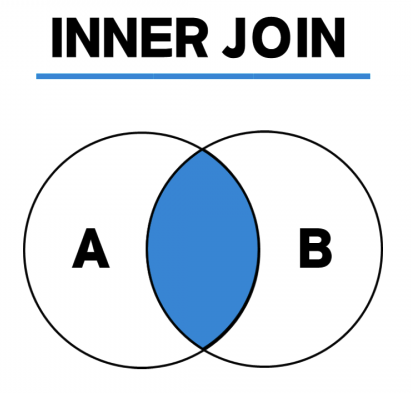
INNER JOIN
각 테이블에서 조인 조건에 일치되는 데이터만 가져오는 조인
여러 테이블을 사용할 때 조인조건을 제대로 기술하지 않으면 크로스조인을 한 결과가 나온다
-- 문제1: 이소미 사원의 사원번호, 직위, 부서번호, 부서명을 보이시오SELECT사원.이름,사원.사원번호,사원.직위,부서.부서번호,부서.부서명FROM사원INNERJOIN부서ON사원.부서번호=부서.부서번호WHERE사원.이름='이소미';-- 문제2: 고객 회사들이 주문한 주문건수를 주문건수가 많은 순서대로 보이시오-- 이때 고객회사의 정보로 고객번호, 담당자명, 고객회사명을 보이시오SELECT고객.고객번호,고객.담당자명,고객.고객회사명,count(*)주문건수FROM고객INNERJOIN주문ON고객.고객번호=주문.고객번호GROUPBY1ORDERBY주문건수desc;-- 문제3: 고객별 주문금액 합을 보이되, 주문 금액 합이 많은 순서대로 보이시오-- 이때 고객회사의 정보로 고객번호, 담당자명, 고객회사명을 보이시오SELECT고객.고객번호,고객.담당자명,고객.고객회사명,SUM(주문수량*단가)주문합FROM고객INNERJOIN주문ON고객.고객번호=주문.고객번호INNERJOIN주문세부ON주문.주문번호=주문세부.주문번호GROUPBY1ORDERBY주문합desc;-- 문제4: 고객 테이블에서 담당자가 이은광인 경우 -- 고객번호, 고객회사명, 담당자명, 마일리지와 마일리지 등급을 보이시오-- *공통된 컬럼이 없는데, 조인을 하는 예외적인 방법*SELECT고객.고객번호,고객.담당자명,고객.마일리지,마일리지,등급명FROM고객INNERJOIN마일리지등급M-- alias ON마일리지등급BETWEEN하한마일리지AND상한마일리지-- 이렇게 join에 대한 조건 작성 가능 WHERE담당자명='이은광';
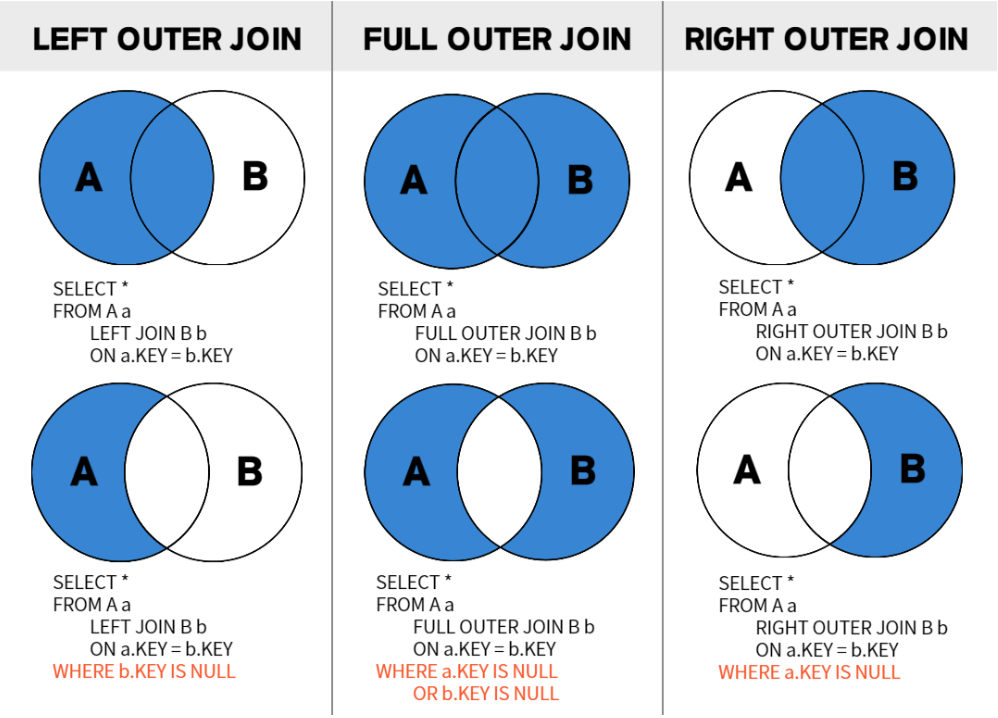
OUTER JOIN
조건이 맞지 않는 행도 함께 출력할 수 있음. 외부 조인은 두 테이블에서 한쪽에는 데이터가 있고, 한쪽에는 없는 경우 데이터가 있는 쪽의 테이블을 기준으로 데이터를 출력한다. MySQL에서 외부조긴은 ANSI SQL 방식으로만 표현 가능!
이너조인은 양쪽 모두 데이터가 있어야 가능하지만, 외부조인은 한쪽에 데이터가 없더라도 조인이 가능하다. 이때 없는 데이터에 대해서는 모두 null로 채워진다. 따라서 외부조인을 사용할 때 어느쪽 방향으로 조인을 해주는 지 설정하는 것이 중요하다. (데이터가 많은 쪽으로 조인을 해주는 것이 옳다) 이런 것들을 잘하기 위해서는 각 테이블과 컬럼, 각 데이터들간의 관계를 잘 알아야한다.
OUTER는 생략가능
LEFT JOIN
왼쪽에 있는 테이블의 결과를 기준으로 오른쪽 테이블 데이터 매칭
매칭되는 데이터가 없는 경우에는 null로 표시
RIGHT JOIN
오른쪽에 있는 테이블의 결과를 기준으로 왼쪽 테이블 데이터 매칭
매칭되는 데이터가 없는 경우에는 null로 표시
외부조인을 사용할때 별도의 방향을 정해주지 않으면 FULL OUTER JOIN이 된다는 것을 잊지말자.
-- 문제: 사원번호, 이름, 부서명을 출력하는데, 성별이 여자인 사람을 출력 SELECT사원번호,이름,부서명FROM사원LEFTJOIN부서ON사원.부서번호=부서.부서번호WHERE성별='여';
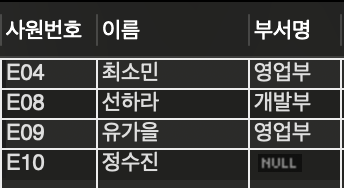
위 문제의 경우, 사원 테이블에는 부서번호, 사원번호, 이름, 성별 컬럼이 존재하고, 부서 테이블에는 부서번호, 부서명이 존재했다. 따라서 부서 테이블을 사원테이블에 조인시키고 각 테이블은 공통된 부서번호로 연결시켰다. 이때 아래 이미지를 보면 부서명이 존재하지 않는 사원에 대해서도 null이 들어감으로써 테이블이 제대로 만들어진 것을 볼 수 있다. 이렇듯 데이터가 존재하지 않아도 조인을 하기 위해서 외부조인을 사용하는 것을 알 수 있다.
즉, 부서명이 없는 정수진이라는 사람의 데이터도 얻기 위해서는 외부조인을 사용해야한다.
-- 문제: 부서명과 해당 부서의 소속사원 정보를 보이시오.-- 이때 사원이 한명도 존재하지 않는 부서명이 있다면 그 부서명도 보이시오.SELECT*FROM부서LEFTJOIN사원ON사원.부서번호=부서.부서번호;
없는 사원에 대한 데이터까지 보고싶은 것이기 때문에 부서에 대해 사원을 외부 조인 해줘야 한다.
이렇듯 원하는 기준이 무엇이냐에 따라 어느쪽으로 조인을 할지 잘 선택하는 것이 중요하다. 그리고 그 방향을 설정하고 난 다음에는 데이터를 어떻게 뽑아올 지 잘 고민해봐야할 것 같다. 별개로 위에서 또 중요한 점은 is null을 사용했다는 것이다. 외부조인에 is null을 사용함으로서 겹치는 영역이 없는 한쪽 테이블의 값을 가져올 수도 있다.
이 이미지를 잊지말자.
SELF JOIN
동일한 테이블 내에서 한 컬럼이 다른 컬럼을 참조하는 조인
동일한 테이블명이 조인조건에 두번 나타나는 것이 특징으로, 이때 테이블명을 다른 별명으로 지정해 다른 테이블인 것처럼 사용한다. 이때 컬럼명도 동일하기 때문에 컬럼명 또한 별명을 지어줌으로써 컬럼의 소속 또한 구분해주어야 한다.
-- 문제1: 사원번호, 사원의 이름, 상사의 사원번호, 상사의 이름을 보이시오SELECT사원.사원번호,사원.이름,상사.사원번호as상사번호,상사.이름as상사이름FROM사원,사원AS상사WHERE상사.사원번호=사원.상사번호;-- 문제2: 사원이름, 직위, 상사이름을 상사이름 순으로 정렬하여 나타내시오.-- 이때 상사가 없는 사원의 이름도 함께 보이시오
-- 고객테이블에서 '서울특별시' 고객에 대해 마일리지합, 평균, 최소, 최대값을 조회SELECTSUM(마일리지),AVG(마일리지),MIN(마일리지),MAX(마일리지)FROM고객WHERE도시='서울특별시';
집계함수의 활용 2. GROUP BY절
그룹별로 묶어서 요약할 때 사용
SELECT 절에 그룹으로 묶을 컬럼명과 집계함수를 넣음
SELECT 절의 집계함수를 제외한 나머지 컬럼이나 수식은 반드시 GROUP BY 절에 넣어야 오류발생이 없음
-- 문제1: 고객 테이블에서 도시별 고객의 수와 해당 도시 고객들의 마일리지 평균을 구하시오SELECT도시,COUNT(*),AVG(마일리지)FROM고객GROUPBY1;-- 문제2: 위 문제에서 중복된 도시를 제거한 데이터를 구하시오SELECTDISTINCT도시,COUNT(*),AVG(마일리지)FROM고객GROUPBY1;-- 문제3: 담당자직위별로 묶고, 같은 담당자직위에 대해서는 도시별로 묶어 집계한 결과-- 고객수와 평균 마일리지를 보이시오. 이떄 담당자직위, 도시순으로 정렬하기 SELECT담당자직위,도시,COUNT(*)고객수,AVG(마일리지)AS'평균 마일리지'FROM고객GROUPBY1,2ORDERBY1,2
집계함수의 활용 3. HAVING 절
GROUP BY 결과에 대해 추가 조건을 넣고자 할 때 사용\n
이때 SELECT 절에 있는 컬럼과 함수에 대한 조건만 넣을 수 있다!
-- 문제1: 고객 테이블에서 도시별로 그룹을 묶어 고객수와 평균마일리지를 구하고,-- 이중에서 고객수가 10명 이상인 레코드만 걸러내시오SELECT도시,COUNT(*)고객수,AVG(마일리지)FROM고객GROUPBY1HAVING고객수>=10;-- 문제2: 고객번호가 T로 시작하는 고객에 대해 도시별로 묶어서 고객의 마일리지를 구하시오-- 이떄 마일리지의 합이 1000점 이상인 레코드만 보이시오SELECT도시,SUM(마일리지)FROM고객WHERE고객번호LIKE'T%'GROUPBY1HAVINGSUM(마일리지)>=1000;
집계함수 심화 1. WITH ROLLUP
그룹별 소계와 전체 총계를 한번에 확인하고 싶을 떄 사용\n
GROUP BY 절 다음에 WITH ROLLUP을 붙여 사용
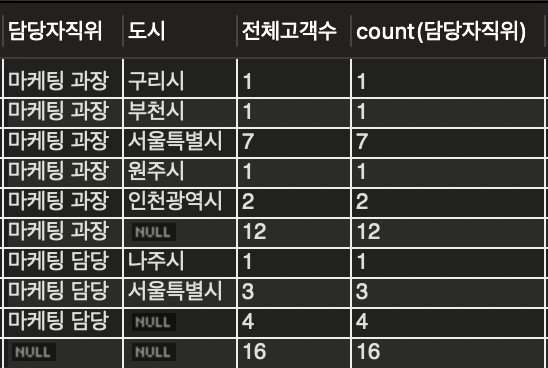
-- 문제1: 지역이 null인 고객에 대해 도시별 고객수, 평균 마일리지를 보이시오-- 이때 마지막 행에 전체 고객수와 전체 고객에 대한 평균 마일리지도 함께 보이시오SELECT도시,COUNT(*),AVG(마일리지)FROM고객WHERE지역ISNULLGROUPBY1WITHROLLUP;-- 문제2: 담당자직위에 마케팅이 들어가있는 고객에 대해 도시별 고객수, 평균 마일리지를 보이시오-- 담당자직위별 고객수와 전체 고객수도 함꼐 볼수 있도록 조회SELECT담당자직위,도시,COUNT(*),AVG(마일리지)FROM고객WHERE담당자직위LIKE'%마케팅%'GROUPBY1,2WITHROLLUP;
이렇게 마케팅 과장에 대한 고객수 합, 마일리지 평균 & 마케팅 담당에 대한 고객수 합, 마일리지 평균이 총계로 나와있는 것을 확인할 수 있다.
집계함수 심화 2. GROUPING
WITH ROLLUP 결과로 나온 NULL에 대해 1을 반환하고, 그렇지 않으면 0을 반환
-- 문제: 담당자직위가 대표 이사인 고객에 대해 지역별로 묶어 고객수를 보이고 전체고객수를 같이 보이시오SELECT지역,COUNT(*)FROM고객WHERE담당자직위='대표 이사'GROUPBY1WITHROLLUP;
이때 결과의 맨위 null은 실제 진짜 데이터상 존재하는 null의 합이고 마지막 null은 WITH ROLLUP을 통해 나온 총계를 의미한다. 이렇듯 각각의 NULL을 구분하기 위해 사용하는 것이 GROUPING이다.
이렇게 WITH ROLLUP에 결과로 나온 null 값에는 1, 그렇지 않은 곳에는 0이 적혀있는 것을 볼 수 있다.
집계함수 심화 3. GROUP_CONCAT()
각 행의 값을 결합
-- 문제1: 사원테이블에 있는 이름을 한 행에 나열하시오SELECTGROUP_CONCAT(이름)FROM사원;-- 문제2: 고객테이블에 들어있는 지역을 한행에 나열하되 중복되는 지역은 한번만 보이시오 SELECTGROUP_CONCAT(distinct지역)FROM고객;-- 문제3: 고객테이블에서 도시별로 고객회사명을 나열하시오SELECT도시,GROUP_CONCAT(고객회사명)FROM고객GROUPBY도시;
문제를 풀어보자
문제1
주문테이블에서 요청일보다 발송이 늦어진 주문내역이 월별로 몇건씩인지 요약하시오. 이때 주문월 순서대로 정렬하시오

 지혜의 개발공부로그
지혜의 개발공부로그